Python
python常用的网站:
Python中的内置函数: https://docs.python.org/zh-cn/3.13/library/functions.html
Python中的模块: https://docs.python.org/zh-cn/3.13/py-modindex.html
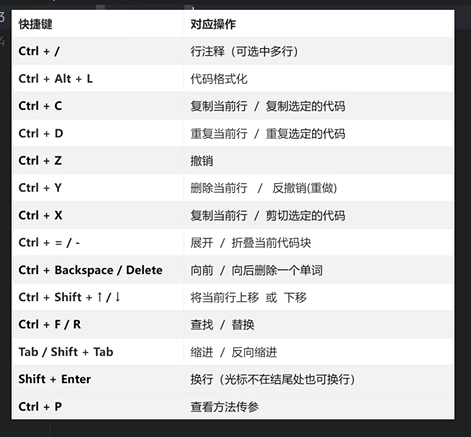
1. pycharm常用快捷键
2. 字面量
字面量就是写在代码中的具体的值
例如下面的值
"张三"
18
65.2
"李四"
55
74.6
"王五"
25
80写在pythOn 文件头部的字符串,会被自动识别成docstring,也就是文档字符串。文档字符串必须使用三个字符串包裹。
3. 变量
在python中,变量其实就是一个代号,用来和某个值建立绑定关系
之所以交变量,是因为他和某个值的绑定关系,可以随时改变
语法: 变量名 = 值
name = '张三'4. 标识符的命名规则
1. 只能包含: 数字、字母、下划线,且不能以数字开头,不饿能包含空格
2. 标识符区分大小写
2. 标识符不能使用关键字
3. 标识符尽量不要与内置函数同名
4. 标识符虽然没有长度限制,但应追求: 简洁清晰,具有描述性5. 常量
一旦被赋值,不希望被修改的变量,称之为常量
常量命名规则:
- 常量名通常使用大写字母,多个单词之间用下划线连接
- 常量一旦赋值,就不能被修改
Python中没有强制的常量机制,Python中所谓的变量,其本质其实还是变量,只不过我们约定好不去修改
例如
AGE = 186. 注释
在python中多行注释的本质就是三个字符串包裹的一段文字
单行注释: #
多行注释: ''' ''' 或 """ """
文档编码注释: 写在python文件头部,用于指定当前文件的字符编码
单行注释不能换行,只有多行注释才可以换行
字符编码
存数据时采用的编码格式,决定了数据读取的编码格式。两者必须一致
7. 数据类型
字符串(str)
整形(int)
浮点型(float)
布尔值(bool)
在python中,可以使用type()函数,查看某个值的数据类型
在python中,变量是没有类型的,值是有类型的
8. 整型
# 所谓整型,就是没有小数点的数字,可以是正数,也可以是负数,也可以是0
import sys
age = 18
temp = -15
score = 0
# 当数很大时,我们可以使用下划线将数字进行分组,来让数字变得更易读
salary = 300_000
house_price = 3_200_000
# python中整数的上限值,取决于执行代码的计算机的内存和处理能力
a = 9 ** 9999
sys.set_int_max_str_digits(0)
b = a + 100
print(b)9. 浮点型
# 浮点型就是带有小数点的数字
weight = 65.2
balance = 1425.58
out_temp = -25.2
price = 120.0
print(type(weight))
print(type(balance))
print(type(out_temp))
print(type(price))
# 浮点型的科学计数法表示.
speed_of_sound = 3.4e+2 #3.4乘以10的2次方
world_population = 7.8e9 #7.8乘以10的9次方
distance_sun_earth = 1.496E8 #1.496 乘以10的8次方
print(speed_of_sound)
print(world_population)
print(distance_sun_earth)
one_ml = 1e-3 # 1乘以10的-3次方10. 字符串的四种定义方式
# 单引号和双引号是不能直接换行的
# 单引号和双引号的写法是等价的,二者都不能直接换行(要用圆括号才能换行),单引号用的多
message1 = '尚硅谷,让天下没有难学的技术!'
message2 = "尚硅谷,让天下没有难学的技术!"
# 三个单引号的写法,可以直接换行,并且可以作为多行注释使用
message3 = '''尚硅谷,让天下没有难学的技术!'''
# 三个双引号的写法,可以直接换行,也可以作为多行注释使用,还能作为文档字符串使用
message4 = """尚硅谷,让天下没有难学的技术!"""
print(message1)
print(message2)
print(message3)
print(message4)11. 格式化输出
name = "张三"
gender = "男"
weight = 35.2
age = 12
# 写法一: 直接用加号进行拼接,写起来很麻烦且代码很乱,而且只能是字符串之间拼接
info1 ='我叫' + name + '我是,' + gender + '生'
print(info1)
# 写法二: 使用占位符
# %s占位字符串,%f 展位浮点数, %i占位整数,%d占位十进制的整数,%s是万能的
info2 ='我叫%s,我是%s生,我的体重是%f,年龄是%d' % (name,gender,weight,age)
print(info2)
# 写法三: 使用f-string (最推荐的方式)
info3 = f'我叫{name},我是{gender}生,我体重是{weight},年龄是{age}'
print(info3)12. 字符串占位符精度控制
字符串占位
%m.ns
m:
- 字符串的最小宽度,位数不够会自动使用空格补齐,位数小于字符串长度则不起作用
- 正数是右对齐,负数是左对齐
n:
- 精度控制,最多输出n个字符(若n大于实际字符串长度,则不起作用)
字符串占位
%m.nf
m:
- 控制整体宽度(整体宽度 = 整数宽度 + 小数点 + 小数宽度)
- 位数不够空格来补,位数小于整体宽度,则自动失效
- 正数是右对齐,负数是左对齐
n:
- 精度控制,保留n位小数,默认值是6,不够6位是会使用0补位,如果需要截断,是需要四舍五入的
整数占位
%m.nd
m:
- 最小宽度,位数不够会自动使用空格补齐,位数小于整数位数,则自动失效
- 正数是右对齐,负数是左对齐
n:
- 精度控制,含义: 最少用n位显示数字
- 位数不够用0来补,位数小于整数位,则自动失效
# 字符串占位符精度控制
"""
字符串的占位
%m,n
m是字符串的宽度
n是字符串的精度
m是正数,向右对齐
m是复数,向左对齐
浮点数的占位
精度控制,保留n位小数,默认值是6,不够6位是会使用0补位,如果需要截断,是需要四舍五入的
整数的占位
m过小自动失效
m过大使用空格补齐
n过小,自动失效
n过大,使用0补齐
"""
name = "张三"
gender = "男"
weight = 35.2
age = 12
info ='我叫%4.4s,我是%s生,我的体重是%f,年龄是%d' % (name,gender,weight,age)
print(info)13. 转义字符
# 转移字符
# 写法一: 使用双引号
print("在python中,可以使用'包裹一个字符串")
# 写法二:使用转移字符
print('在python中,可以使用\'包裹一个字符串')
print('在python中,可以使用\"包裹一个字符串')
# 使用\n进行换行
print("注册会员需要以下信息: \n姓名\n年龄\n手机号")
# 使用\\输入\
print("\\")
# 使用\b 删除前一个字符
print("helloo\b")
# 使用 \r 使光标回到本行开头,覆盖输出
print('67%\r68%')
# 使用 \t: 水平制表符(让光标跳转到下一个制表位)
print('ab\tcd')
# 表明在什么环境下,制表位都是4个空格
print('ab\tcd'.expandtabs(4))
print('abc\td'.expandtabs(4))14. 数据类型转换
把指定数据转为字符串,任何类型都可以转成字符串类型
result1 = str(18)
result2 = str(75.6)
print(result1)
print(result2)使用str()将指定数据转换为字符串
result1 = str(18)
result2 = str(75.6)
result3 = str(1.8e3)
result4 = str(12_000)
print(type(result1), result1)
print(type(result2), result2)
print(type(result3), result3)
print(type(result4), result4)把指定数据转为整型: int()
result5 = int(15.6)
result6 = int("79")
result7 = int(" 79 ")
result8 = int(48)
print(type(result5), result5)
print(type(result6), result6)
print(type(result7), result7)
print(type(result8), result8)把指定数据转为浮点型: float()
result9 = float(18)
result10 = float("15.6")
result11 = float(" 5.7 ")
result12 = float(14.8)
result13 = float("48")
print(type(result9), result9)
print(type(result10), result10)
print(type(result11), result11)
print(type(result12), result12)
print(type(result13), result13)把指定数据转为布尔类型: bool()
Python中除0以外的任何数,转为布尔值后都为True,只关心是不是0,0为False,非0为True
result9 = float(18)
result10 = float("15.6")
result11 = float(" 5.7 ")
result12 = float(14.8)
result13 = float("48")
print(type(result9), result9)
print(type(result10), result10)
print(type(result11), result11)
print(type(result12), result12)
print(type(result13), result13)Python中除空字符串以外的任何数,转为布尔值后都为True
15. 算数运算符
# 算数运算符
"""
+ 加
- 减
* 乘
/ 除
// 取整
% 取模或取余
** 指数
"""16. 赋值运算符
age = 18 #赋值运算符
age = age + 1 等价于 age += 1 # 加法 复合赋值运算符
age = age - 1 等价于 age -= 1 # 减法 复合赋值运算符
age = age / 2 等价于 age /= 1 # 除法 复合赋值运算符
age = age // 2 等价于 age //= 1 # 取整 复合赋值运算符
age = age % 2 等价于 age %= 1 # 取模 复合赋值运算符
age = age % 2 等价于 age %= 1 # 取模 复合赋值运算符
age = age ** 2 等价于 age **= 1 # 指数 复合赋值运算符17. 比较运算符
== 判断左右两侧是否相等
!= 判断左右两侧是否不相等
> 判断左侧是否大于右侧
>= 判断左侧是否大于等于右侧
< 判断左侧是否小于右侧
<= 判断左侧是否小于等于右侧18. 布尔类型
# 布尔类型
a = True
b = False
c = 7 > 3
d = 7 < 2
print(type(a),a)
print(type(b),b)
print(type(c),c)
print(type(d),d)
# 布尔类型是int类型的子类型,底层的本质是用1表示True, 用0表示False
print(4 + True) # 5
print(8 - False) # 8
print(True + True) #2
print(False - False) #0
# 使用bool将指定内容转换为布尔类型
print(bool(1))
print(bool(0))19. 逻辑运算符
# and 用于判断其两侧的值,是否都为True
print(True and True)
print(True and False)
print(False and True)
print(False and False)
# and具备逻辑短路的能力
print(False and 3/0) # False
# and返回的不一定是布尔值,它返回的是某个参与计算的值本身
# 规则: and会先看左边,如果左边是"假",就直接返回左边,否则返回右边
# 备注: 若参与and的值不是布尔值,那Python会自动转换为布尔值,然后再进行逻辑操作
# or 用于判断其两侧,是否至少有一个为True(只要有一个是True,那就返回True)
print(True or True)
print(True or False)
print(False or True)
print(False or False)
# or具备逻辑短路的能力
print(True or 3/0)
print(9 > 3 or 3/0)
# or返回的也不一定是布尔值,它返回的是参与计算的值本身
# 规则: or会先看左边,如果左边是"真",就直接返回左边,否则返回右边
# 备注: 若参与or的值不是布尔值,那Python会自动转换为布尔值,然后再进行逻辑操作
# not 用于取反
# 备注: 若参与not的值不是布尔值,那Python会自动转换为布尔值,然后再进行逻辑操作
print(not True)
print(not False)
print(not 3 > 2)
print(not 3 < 2)
#not 返回的值,一定是布尔值20. 进制
10进制转其他进制字符串
bin(10) # 十进制转二进制字符串
oct(10) # 十进制转八进制字符串
hex(10) # 十进制转十六进制字符串
其他进制转为十进制数字
使用int()将指定进制的数,转为十进制数字
int('0b11001', 2) # 转为二进制
int('0o1034', 8) # 转为八进制
int('0x1cf', 16) # 转为十六进制
21. 输入语句
name = input("请输入你的姓名: \n")
age = input("请输入你的年龄: \n")
age = int(age)
print(f'{name},你今年的年龄是{age}')
print(f'{name},你明年的年龄是{age + 1}')22. 流程控制语句
单分支(基于判断实现)
age = input("请输入您的年龄: \n")
age = int(age)
if age >= 18:
print('你是成年人')
print('成年人的世界,虽不容易,但很精彩!')
print("================================")双分支
age = input("请输入您的年龄: \n")
age = int(age)
if age >= 18:
print('你是成年人')
print('成年人的世界,虽不容易,但很精彩!')
else:
print("你是未成年人")
print("好好加油,努力学习,未来可期!")
print("欢迎你来学习python")多分支
age = input("请输入您的年龄: \n")
age = int(age)
if age <= 10:
print('你是幼儿')
elif age <= 18:
print("你是青少年")
elif age <= 30:
print("你是青年")
elif age <= 50:
print("你是中年")
elif age <= 60:
print("你是中老年")
else:
print("您是老年")嵌套分支
age = input("请输入您的年龄: \n")
has_report = input("您是否提交了体检报告?(是/否)")
level = int(input('请输入您的会员等级(1/2/3)'))
age = int(age)
print("*****程序的识别结果如下******")
if 18 <= age <= 45:
print("您的年龄符合比赛要求!")
if has_report == '是':
print("您已提交体检报告!")
print("您可以参加比赛")
if level == 1:
print(f'尊敬的{level}级会员,比赛结束后,您可以领取纪念T恤一键')
elif level == 2:
print(f'尊敬的{level}级会员,比赛结束后,您可以领取纪念T恤一键')
elif level == 3:
print(f'尊敬的{level}级会员,比赛结束后,您可以领取纪念T恤一键')
else:
print("您的会员等级不符")
elif has_report == '否':
print("您未提交体检报告,不能参加比赛")
else:
print("您输入的体检报告有误!")
else:
print("抱歉,您的年龄不符合比赛要求!")23.while循环
n = 1
while n <= 10:
print(f'你好啊====={n}')
n += 1案例
print("您现在身处密室,需要正确回答问题之后,才能逃出密室!")
riddle = '你是什么人?'
answer = '你的心上人'
guess = ''
while guess != answer:
print(f'问题: {riddle}')
guess = input('请输入答案:\n')
if guess == answer:
print('答案正确,逃脱成功!')
else:
print('回答错误,请再想想!')24.for循环
for 当前取出的值 in 可迭代对象: 要执行的循环操作1 要执行的循环操作2
for n in range(10):
print('你好啊',n)25. while循环与for循环的区别
- while循环是先判断条件,再执行循环体
- for循环是先取出可迭代对象中的值,然后再执行循环体
- 一般情况下,for循环的性能要优于while循环
- 当不确定循环次数时,使用while循环;当确定循环次数时,使用for循环
26. for循环实现99乘法表
for i in range(1, 10): # 外层循环控制行数
for j in range(1, i + 1): # 内层循环控制列数,从1到当前i的值
print(f'{j}x{i}={i*j}', end='\t') # 打印乘法表的一项并使用制表符分隔
print() # 每完成一行后换行27. contine 和 break
- continue 和 break 在for循环和wile循环中都可以使用
- continue 用于结束本次循环,但不退出整个循环
- break 用于结束整个循环
- coontinue 和 break 都只在当前循环有效
28. 流程控制综合案例
# 流程控制综合案例
print('欢迎来到: 答题闯关挑战赛(输入q可随时退出)')
# 题目与答案
ques1,ans1 = 'Python中用于输入的函数是?','print'
ques2,ans2 = 'Python中用于表示逻辑“并且”的关键字是?','and'
ques3,ans3 = 'Python属于编译型还是解释型?','解释型'
# 最多可尝试次数
max_tries = 3
# 总关卡数
total_levels = 3
# 是否处于可游戏状态
is_playing = True
for level in range(1,total_levels + 1):
print(f'*********第{level}关*********')
if level == 1:
question,answer = ques1,ans1
elif level == 2:
question, answer = ques2, ans2
else:
question, answer = ques3, ans3
# 若已经尝试的次数,小于等于最大尝试次数,则进入循环
tries = 1
while tries <= max_tries:
user_input = input(f'{question} \n')
if user_input == answer:
print('回答正确!')
break
elif user_input == '':
print('您的输入为空,请重新作答!')
continue
elif user_input == 'q':
print('您已退出游戏!')
is_playing = False
break
else:
# 计算剩余次数
leave = max_tries - tries
if leave > 0:
print(f'回答错误,您还剩{leave}次机会!')
tries += 1
continue
else:
print(f'挑战失败,本题的正确答案是: {answer},游戏结束!')
is_playing = False
continue
if not is_playing:
break
if is_playing:
print('恭喜您,全部通关')29. 函数
函数是组织好的、可重复使用的、用于执行特定任务的代码块
Python中函数的分类
- 内置函数
无需要任何操作,直接就能使用的函数 - 模块提供的函数
需要导入指定的模块后,才能使用。 - 自定义函数
程序员自己定义的函数(先定义再使用)
30. 函数的基本使用
# 函数
def welcome():
print('欢迎来到尚硅谷课堂!')
print('尚硅谷,让天下没有难学的技术!')
welcome()31. 函数参数的使用
# 函数参数的使用
def order(num, dish):
print(f'您点的是: {num}份 {dish}')
order(1, '辣椒炒肉')32. 函数_位置参数
# 位置参数
# 位置参数: 调用函数时,根据参数在函数定义中出现的顺序,把实参的值一次传递给对应的形参
def greet(name,gender,age,height):
print(f'我叫{name},性别{gender},年龄{age}岁,身高是{height}cm')
greet('张三','男',18,172)33. 函数_关键字参数
使用关键词参数时,位置参数必须在关键字参数之前
# 关键字参数: 在调用函数时,根据形参的名字来传递实参的值
def greet(name,gender,age,height):
print(f'我叫{name},性别{gender},年龄{age}岁,身高是{height}cm')
greet(name='张三', age=18, gender='男', height=172)34. 限制传参方式
具体规则:
- /前边只能用位置参数,*后面只能用关键字参数
- / 和 * 同时使用时,/必须在*前面
# 限制传参方式
#具体规则: /前边只能用位置参数,*后面只能用关键字参数
# / 和 * 同时使用时,/必须在*前面
def greet(name,/,gender,*,age,height):
print(f'我叫{name},性别{gender},年龄{age}岁,身高是{height}cm')
# greet('张三','男',18,172)
greet('张三', age=18, gender='男', height=172)35. 默认参数
定义函数时,通过形参名=值的形式,为参数指定一个默认值
默认参数必须要放在必选参数的后面,或者说: 某个形参,一旦设置了默认值,那么该参数就必须放在非必选参数的后面
如果没传默认参数,那么该参数使用默认值,如果传了默认参数,那么该参数使用传入的值
def greet(name,gender='男',age=18,height=172):
print(f'我叫{name},性别{gender},年龄{age}岁,身高是{height}cm')
greet('张三')36. 可变参数
位置参数: 定义函数时,在形参名前加*,表示该参数可以接收任意数量的位置参数,并打包成一个元组
关键字参数:定义函数时,在形参名前加**,表示该参数可以接收任意数量的关键字参数,并打包成一个字典
可变位置参数、可变关键字参数,可以同时使用,但必须先写可变位置参数
可变位置参数,可变关键字参数,也能与其他类型的参数一起使用
# 定义函数(使用*args)去接收: 可变位置参数
# 定义函数(可变位置参数)
def test1(*args):
print(args)
test1('张三','男',18,172)
# 定义函数(可变关键字参数)
def test2(**kwargs):
print(kwargs)
test2(name='张三',gender='男',age=18,height=172)
# 定义函数(同时使用,可变位置参数,可变关键字参数)
def test3(*args,**kwargs):
print(args)
print(kwargs)
test3('张三','男',age=18,height=172)37. 特殊的字面量_None
# None
#NoneType类型: None
# 1.None是一个特殊的字面量,它表示: 空值/无值/无意义
msg = None
# 2.None的类型是NoneType
print(type(msg))
# 3.None转为布尔值是False
print(bool(msg))
# 4.None不能参与数学运算,也不能与字符串拼接
# result1 = msg + 1
# 5.不给函数设置返回值,函数会默认返回None38. 函数的返回值
函数返回值: 函数执行完毕后,会把执行结果交给调用者,这个执行结果就是返回值
return关键字: retrun会结束函数执行,并把return后的值,作为函数的返回值
def add(n1,n2):
print(f'我收到了: {n1}、{n2},二者相加是: {n1 + n2}')
return n1 + n2
result = add(100,200)39. 全局作用域 vs 局部作用域 以及global关键字的使用
什么是作用域? ---- 变量能起作用的范围(变量在哪里能用,在哪里不能用)。
- 全局作用域: 整个.py文件最外层的范围,就是全局作用域
- 局部作用域: 在函数内部,就是局部作用域,只能在当前函数中使用
局部作用域和局部作用域,会在函数调用时创建,在函数执行后销毁
# 全局作用域和局部作用域
a=100
b=200
def test():
c='尚硅谷'
d='你好啊'
a = 300
print(a) # 300
print(b)
print(c)
print(d)
test()
print(a) # 100
print(b)
# print(c) 报错
# print(d) 报错
def test():
c='尚硅谷'
d='你好啊'
global a # 声明n是全局变量
a = 300
print(a) # 300
print(b)
print(c)
print(d)
test()
print(a) # 300
print(b)
# print(c) 报错
# print(d) 报错40. 函数的嵌套调用
在一个函数的执行过程中,去调用了另外一个函数
41. 函数的递归调用
递归调用: 是指函数自己调用自己的一种操作。
# 递归调用
def welcome(n):
print(f'你好啊!----------{n}')
if n > 1:
welcome(n - 1)
welcome(5)
# 输出
# 你好啊!----------5
# 你好啊!----------4
# 你好啊!----------3
# 你好啊!----------2
# 你好啊!----------1
def welcome(n):
if n > 1:
welcome(n - 1)
print(f'你好啊!----------{n}')
welcome(5)
# 输出
# 你好啊!----------1
# 你好啊!----------2
# 你好啊!----------3
# 你好啊!----------4
# 你好啊!----------5原理是: 待执行函数的调用,会形成一个栈结构,当函数执行完毕后,就会从栈中弹出。
这两段代码在递归时,其实都需要逐层压栈,二者调用深度完全相同,只是打印的时机不同。
42. 递归的应用
# 递归的应用
#使用递归求一个数的阶乘
# 某个数的阶乘就是: 所有小于及等于
def factorial(num):
if num == 0:
return 1
else:
return num * factorial(num - 1)
result = factorial(5)
print(result)43. 函数的说明文档
说明文档: 写在函数里的文字说明,用来描述: 函数的功能、需要哪些承诺书、返回什么结果。
# 函数的说明文档
# 接收两个数字: n1、n2,返回二者相加的结果
def add(n1, n2):
"""
计算两个数相加的结果
:param n1: 第一个数
:param n2: 第二个数
:return: 二者相加的结果
"""
return n1 + n2
result = add(100,500)
print(result,'result========')44. 函数_综合案例
# 函数综合案例
def calc_total(*nums):
"""
计算总运动量
:param nums: 每一天的运动量(可变参数)
:return: 总运动量(个)
"""
return sum(nums)
def calc_avg(total, days=3):
"""
计算平均值
:param total: 总运动量
:param days: 天数(默认值是7)
:return: 平均值
"""
return total / days
def check_success(total, goal=120):
"""
判断本次挑战是否成功
:param total: 总运动量
:param goal: 目标运动量
:return: 成功或失败的具体信息
"""
print(total)
print(goal)
if total >= goal:
return '恭喜!挑战成功!'
else:
return '抱歉!挑战失败!'
def main(title, duration,goal):
"""
主函数,用于开始一场挑战赛
:param title: 比赛标题
:param duration: 比赛持续天数
:param goal: 目标运动量
:return: None
"""
print(f'【{title}】【{duration}】天挑战赛(请输入每天的数量)')
num1 = int(input('第1天: '))
num2 = int(input('第2天: '))
num3 = int(input('第3天: '))
# 计算总数
total = calc_total(num1, num2, num3)
# 计算平均值
avg = calc_avg(total,duration)
# 判断挑战是否成功
result = check_success(total,goal)
print(f'【{title}】【{duration}】天健身总结')
# print('总数: %d,平均数: %.1f'% (total, avg))
print(f'总数: {total},平均数: {avg:.1f}')
print(result)
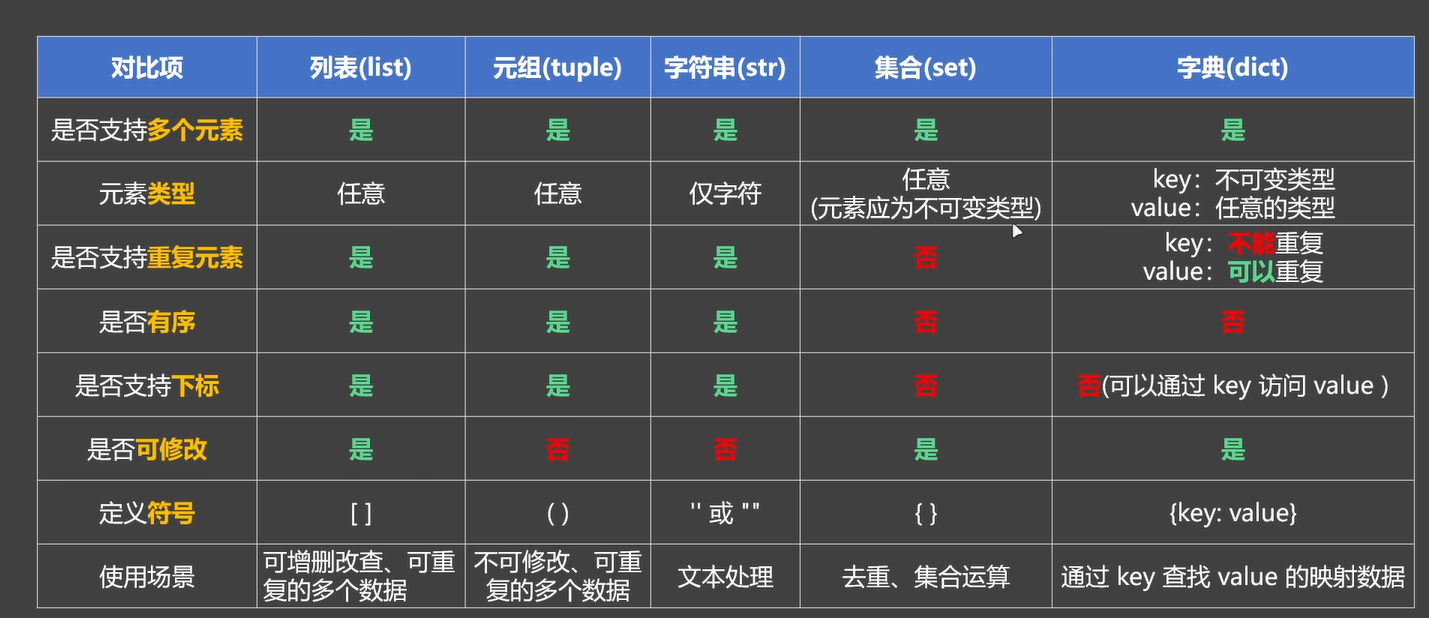
main('仰卧起坐', 3,30)45.数据容器
1. 何为数据容器
数据容器: 一种能存放多个数据的数据类型
数据容器可以更高效的管理成批的数据,且便于存储、访问
容器中的每一个数据,又称: 每一个元素 Python中有很多中数据容器
2. 列表
1. 定义列表
# 列表
list1 = [34,56,21,56,11]
list2 = ['北京','尚硅谷','你好啊']
list3 = [23,'尚硅谷',True,None]
list4 = [23,'尚硅谷',True,None,[100,200,300]]
# 定义空列表(列表中的数据,后期会通过特定写法填充)
list5 = []
list6 = list()
print(list1,type(list1))
print(list2,type(list2))
print(list3,type(list3))
print(list4,type(list4))
print(list5,type(list5))
print(list6,type(list6))2. 列表_ 下标
下标(索引值): 列表中元素的位置编号
正索引: 从左往右数,起始元素是0,随后是1,依次类推 负索引: 从右往左数,起始元素是-1,随后是-2,依次类推
#定义一个列表
nums = [10,20,30,40,50]
# 正索引
print(nums[0])
print(nums[1])
print(nums[2])
print(nums[3])
print(nums[4])
# 负索引
print(nums[-1])
print(nums[-2])
print(nums[-3])
print(nums[-4])
print(nums[-5])
# 定义一个嵌套列表
nums2 = [10,20,['你好啊','尚硅谷'],40,50]
# 取出"尚硅谷"
print(nums2[2][1])3. 列表_增删改查
新增操作:
append() 添加元素到列表的末尾
insert() 在列表的指定位置插入一个元素
extend() 将可迭代对象中的内容一次取出,追加到列表的尾部
删除操作:
pop() 删除指定位置的元素,并返回被删除的元素 语法: 列表.pop(下标) 默认删除最后一个元素,返回被删除的元素值
remove() 删除列表中第一次出现的指定元素 语法: 列表.remove(元素值)
clear() 清空列表中的所有元素 语法: 列表.clear()
del 列表下标 删除指定位置的元素 语法: del 列表[下标]
# 定义一个空列表
nums = [10,20,30,40]
# 向列表尾部追加一个元素
nums.append(1)
# 语法: 列表.append(元素)
print(nums)
# 在列表指定下标处添加一个元素
nums.insert(2,666)
print(nums)
# 语法: 列表.insert(下标,元素)
# 将可迭代对象中的内容一次取出,追加到列表的尾部
nums.extend([70,80,90])
print(nums)
# 语法: 列表.extend(下标,元素)修改操作:
通过下标修改指定位置的元素 语法: 列表[下标] = 新值
查询操作:
通过下标查询指定位置的元素 语法: 列表[下标]
4. 列表_常用方法
- 列表.index(值) 查找指定元素在列表中第一次出现的下标 返回值: 元素下标 只在第一层列表查找
fruits = ['香蕉','苹果','橙子','香蕉']
result = fruits.index('香蕉')
print(result)
- 列表.count(值) 统计某个元素在列表中出现的次数 返回值: 元素出现的次数
nums = [10,20,10,30,10,40,[10,10,10]]
result = nums.count(10)
print(result)
- 列表.reverse() 反转列表(会改变原列表) 返回值: 无
nums = [10,20,10,30,10,40,[10,10,10]]
nums.reverse()
print(nums)
- 列表.sort(reverse=布尔值) 对列表进行排序(从小到大,会改变原列表) reverse 用于控制排序方式 返回值: 无
nums = [10,20,10,30,10,40,[10,10,10]]
nums.sort(reverse=True)
print(nums)5. 常用的内置容器
1. 使用内置的sorted函数,返回一个排序后的新容器(不改变原容器,默认顺序: 从小到大)
nums = [23,11,32,30,17]
result = sorted(nums)
print(result)2. 使用内置的len函数,获取容器中元素的总数量,返回值是: 元素总数量
nums = [10,20,10,30,10,40,[50,60,70]]
result = len(nums)
print(result)3. 使用内置的max函数,获取容器中的最大值,返回值是: 最大值
nums = [23,11,32,30,17]
result = max(nums)
print(nums)
print(result)4. 使用内置的min函数,获取容器中的最小值,返回值是: 最小值
nums = [23,11,32,30,17]
result = min(nums)
print(nums)
print(result)5. 使用内置的sum函数,对容器中的数据进行求和,元素只能是数值
nums = [23,11,32,30,17]
result = sum(nums)
print(nums)
print(result)5. 列表·循环遍历
把容器中的元素依次取出,并执行后续操作的过程,称为: 循环遍历
1. 使用while循环遍历列表
# 定义一个成绩列表
score_list = [62,50,60,48,80,20,95]
index = 0
while index < len(score_list):
print(score_list[index],end=',')
index += 12. 使用for循环遍历列表
写法1
# 定义一个成绩列表
## for循环遍历
for item in score_list:
print(item,end=',')写法2
# 定义一个成绩列表
## for循环遍历
for index in range(len(score_list)):
print(score_list[index])写法3
可以同时获取index和item
# 定义一个成绩列表
## for循环遍历
for index,item in enumerate(score_list):
print(index,item)enumerate可以传入第二个参数,表示从指定值开始计数
# 定义一个成绩列表
## for循环遍历
for index,item in enumerate(score_list,5):
print(index,item)6. 列表_特点总结
- 可存放不同类型的元素
- 元素是有序存储的(正索引、负索引)
- 列表中的元素允许重复
- 元素是允许修改的(增删改查其他操作)
- 长度不固定,可以随着操作自动调整大小
列表是最常用的数据容器,当遇到要"存储一批数据"的场景时,首选列表
7. 元组
元组是一种和列表类似的数据容器,它和列表的区别是: 元素中的元素不可修改。
# 定义一个元组
t1 = (1,5,6,7,8,9)
print(t1,type(t1))
# 元组中如果存放了可变类型(列表),那可变类型中的内容仍可修改
t3 = (28,67,21,67,11,[100,200,300,('你好','尚硅谷')])
t3[5][2] = 400
print(t3)1. 元组常用的方法
# 获取指定元素在元组中第一次出现的下标
result = t3.index(67)
print(result)
# 统计元组中
result = t3.count(67)
print(result)2. 元组中常用的内置函数
res = max(t3)
print(res)
res = min(t3)
print(res)
res = len(t3)
print(res)
res = tuple(sorted(t3))
print(res)3. 元组的循环遍历
t4 = (28,67,21,67,11)
index = 0
while index < len(t4):
print(t4[index])
index += 14. 函数调用时,使用*对列表或元组进行解包后,再传递参数
def test(*args):
print(f'我是test函数,我收到的参数是: {args}, 参数类型是: {type(args)}')
list1 = [100,200,300,400]
tuple1 = ('你好','北京','尚硅谷')
test(*list1)
test(*tuple1)5. 元组(tuple)_特点
- 可存放不同类型的元素
- 元素是有序存储的(正索引、负索引)
- 元组中的元素允许重复
- 元组中的元素不允许修改
- 元组的长度固定,一旦创建就不能修改大小
元组是一种只读的数据容器,想保存一批"不会变的数据"时,首选元组。
8. 字符串
字符串就是存放多个字符的容器
- 字符串是不可变的
- 字符串不能嵌套
1. 字符串常用的方法
index方法: 获取指定字符在字符串中第一次出现的下标
msg = 'welcome to atguigu'
result = msg.index('t')
print(result)split方法: 将字符串按照指定字符进行分隔,并返回一个列表
msg = '尚硅谷@atguigu@你好'
result = msg.split('@')
print(result)replace方法: 将字符串中的某个字符串片段,替换成目标字符串
msg = 'welcome to atguigu'
result = msg.replace('atguigu','尚硅谷')
print(result)count方法: 统计字符串中某个字符出现的次数
msg = 'welcome to atguigu'
result = msg.count('t')
print(result)strip方法: 从某个字符串中删除指定字符串中的任意字符串
规则: 从字符串两端开始删除,直到遇到第一个不再指定字符串中的字符就停下
默认会去掉字符串两边的空格
msg = '666尚6硅6谷666'
result = msg.strip('6')
print(msg)
print(result)#尚6硅6谷
msg = '1234尚12硅34谷4321'
result = msg.strip('1324')
print(result) #尚12硅34谷2. 常用的内置函数
len函数: 统计字符串中,字符的个数(字符串长度)
max函数:返回字符串中Unicode编码值最大的字符,不是下标
min函数:返回字符串中Unicode编码值最小的字符,不是下标
sorted函数:将字符串按Unicode编码值进行排序,返回一个新的列表
9. 序列
序列: 能联系存放元素的数据容器,元素有先后顺序,且可以通过下标访问
切片: 从序列中按照指定范围,取出一部分元素,形成一个新的序列的操作
语法: 序列[起始索引:结束索引:步长]
list1 = [10,20,30,40,50,60,70,80,90,100]
list2 = list1[0:10:1]
# 等价于
list3 = list1[::]
list4 = list1[:999:]
print(list2)
print(list3)
print(list4)
list5 = list1[3::]
print(list5)
list6 = list1[:5:]
print(list6)
list7 = list1[::4]
print(list7)当起始索引大于结束索引时,步长必须为负数,否则结果是空列表
list8 = list1[7:2:-1]
print(list8)特殊情况: 当同时省略起始索引和结束索引时,如果步长为负数,那Python会自动对调起始索引和结束索引
list9 = list1[::-1]
print(list9)对元组进行切片
tuple1 = (10,20,30,40,50)
tuple2 = tuple1[0:5:1]
print(tuple2)对字符串进行切片
msg1 = 'welcome to atguigu'
msg2 = msg1[0:10:1]
print(msg2)序列的其他操作
相加
心血列 = 序列1 + 序列2
两个同类型的序列才能相加(字符串+字符串、列表+列表、元组+元组)
列表相加
list1 = [10,20,30,40]
list2 = [50,60,70,80]
list3 = list1 + list2
print(list3)元组相加
tuple1 = (10,20,30,40)
tuple2 = (50,60,70,80)
tuple3 = tuple1 + tuple2
print(tuple3)字符串相加
msg1 = 'hello'
msg2 = 'world'
msg3 = msg1 + msg2
print(msg3)相乘(重复)
新序列 = 序列 * n
注意: n必须是整数,不能是浮点数
list1 = [10,20,30,40]
list2 = list1 * 3
print(list2)元组相乘
tuple1 = (10,20,30,40)
tuple2 = tuple1 * 3
print(tuple2)字符串相乘
msg1 = 'hello'
msg2 = msg1 * 3
print(msg2)10. 集合
集合有两个set/frozenset两种类型,二者区别是:frozenset是不可修改的集合
可变集合: 创建后可以增删元素
不可变集合: 创建后不可以增删元素
集合的特点: 内部的元素无序(不保证顺序),不能通过下标访问元素,会自动去除重复元素
1. 集合的定义
可变集合
s1 = {10,20,30,40,50,60,60,70,80,90}
print(type(s1), s1)
s2 = {'你好','你好','hello world'}
print(s2)
print(type(s2), s2)
s3 = {10,'你好',True,1,12.4}
print(type(s3), s3)不可变集合
s1 = frozenset({10,20,30,40,50,60,60,70,80,90})
print(type(s1), s1)
s2 = frozenset({'你好','你好','hello world'})
print(s2)
print(type(s2), s2)
s3 = frozenset({10,'你好',True,1,12.4})
print(type(s3), s3)
# frozenset 接收的参数,可以是任意可迭代对象,但最终返回的一定是[不可变集合]
s4 = frozenset('hello')
print(type(s4),s4)
#集合中不能嵌套【可变集合】,但可以嵌套【不可变集合】
#原因: 集合不支持下标,但底层依然需要给其中的每个元素,分配一个编号,这个编号可以用来:快速定位元素,并且这个编号是哈希值
# 定义空集合(可变集合)
s1 = set()
print(type(s1),s1)2. 集合增删改查
增
# add方法: 向集合中添加元素
s1 = {10,20,30,40,50}
s1.add(60)
print(s1)
# update方法: 向集合中添加元素(必须传递可迭代对象,例如: 列表、元组、集合等)
s1 = {10,20,30,40,50}
s1.update([70,80])
print(s1)删
# 增
# add方法: 向集合中添加元素
s1 = {10,20,30,40,50}
s1.add(60)
print(s1)
# update方法: 向集合中添加元素(必须传递可迭代对象,例如: 列表、元组、集合等)
s1 = {10,20,30,40,50}
s1.update([70,80])
print(s1)
# 删
# remove(元素):从集合中一处指定元素(若元素不存在,报错)
s1 = {10,20,30,40,50}
s1.remove(20)
# s1.remove(70) 报错
print(s1)
#discard(元素): 从集合中移除指定元素(若元素不存在,不报错)
s1 = {10,20,30,40,50}
s1.discard(70)
print(s1)
#pop():从集合中移除一个任意元素,返回值是移除的那个元素
s1 = {10,20,30,40,50}
s1.pop()
print(s1)
#clear(): 清空集合
s1 = {10,20,30,40,50}
s1.clear()
print(s1)改
集合没有下标,也不支持replace方法,所以集合没有专门用于"改"的方法。
可以用: remove + add的组合,来达到"修改"的效果
s1 = {10,20,30,40,50}
s1.remove(30)
s1.update([60])
s1.add(74)
print(s1)查
由于集合没有下标,也不支持切片操作,所以集合不具备按位置访问的能力
通过成员运算符可以判断: 某个元素是否在集合中
3. 集合的常用方法
- 集合A.difference(集合B): 返回一个新集合,包含A中有但B中没有的元素
s1 = {10,20,30,40,50}
s2 = {30,40,50,60,470}
result = s1.difference(s2)
print(result)
print(s1)
print(s2)- 集合A.difference_update(集合B): 让A去掉与B相同的元素
s1 = {10,20,30,40,50}
s2 = {30,40,50,60,470}
result = s1.difference_update(s2)
print(result)
print(s1)
print(s2)- 集合A.union(集合B): 返回一个新集合,包含A和B中所有的元素(求并集)
s1 = {10,20,30,40,50}
s2 = {30,40,50,60,470}
result = s1.union(s2)
print(result)
print(s1)
print(s2)- 集合A.insubset(集合B): 判断A是否是B的子集
s1 = {10,20,30,40,50}
s2 = {10,20}
result = s2.insubset(s1)
print(result)- 集合A.issuperset(集合B): 判断A是否是B的子集
s1 = {10,20,30,40,50}
s2 = {10,20}
result = s1.issuperset(s2)
print(result)- 集合A.isdisjoint(集合B): 判断A和B是否没有交集
s1 = {10,20,30,40,50}
s2 = {10,20,50}
result = s1.isdisjoint(s2)
print(result)4. 集合的数学运算
并集(|)
s1 = {10,20,30,40,50,60}
s2 = {40,50,60,70,80,90}
# 并集
result = s1 | s2
print(result)交集(&)
s1 = {10,20,30,40,50,60}
s2 = {40,50,60,70,80,90}
# 交集
result = s1 & s2
print(result)差集(-)
s1 = {10,20,30,40,50,60}
s2 = {40,50,60,70,80,90}
# 差集
result = s1 - s2
print(result)对称差集(^)
s1 = {10,20,30,40,50,60}
s2 = {40,50,60,70,80,90}
# 对称差集
result = s1 ^ s2
print(result)5. 集合的循环遍历
集合不能使用while循环遍历,可以使用for循环遍历
#集合不能使用while循环遍历,可以使用for循环遍历
s1 = {10,20,30,40,50,60}
for item in s1:
print(item)6. 集合的特点
- 无序: 集合中的元素没有固定顺序,无法通过下标访问
- 不重复: 自动去除重复元素
- 分为两种: 可变集合(set)和不可变集合(frozenset)
- 集合中的元素必须是不可变类型(如: 数字、字符串、元组)
- 集合支持: 并集、交集、差集、对称差集等数学运算
集合是可以去重的数据容器,当只关心元素是否存在,而不在乎顺序时,首选集合
11.字典
1. 字典的定义
字典中的key必须是不可变类型,value可以是任意数据类型
# 字典
d1 = {
'张三': 72,
'李四': 60,
'王五': 85
}
print(type(d1),d1)
d2 = dict()
print(type(d2),d2)2. 字典的增删改查
# 查询
d1 = {'张三': 72,'李四': 60,'王五': 85}
# 直接取值,若键(key)不存在,会报错
# result = d1['张三']
# 安全取值,若键(key)不存在,会返回默认值(若没有设置默认值,则会返回None)
result = d1['张三']
result2 = d1.get('奥特曼','抱歉,key不存在')
print(result)
print(result2)
# 新增
d1 = {'张三': 72,'李四': 60,'王五': 85}
d1['赵六'] = 100
print(d1)
# 批量修改
d1.update({'李四': 50,'王五':100})
print(d1)
# 删除
d1 = {'张三': 72,'李四': 60,'王五': 85}
print(d1)
del d1['张三']
print(d1)
# 删除指定key所对应的那组键值对,并返回这个key所对应的值
# pop方法可以设置默认值
# 默认值可以保证: 当要删除的key不存在的情况下,程序不会报错,并且返回这个默认值
result = d1.pop('李四')
print(d1)
print(result)
# 清空字典
d1.clear()
print(d1)3. 字典的常用方法
# keys方法: 用于获取字典中所有的键
d1 = {'张三': 72,'李四': 60, '王五': 85}
# keys方法的返回值不是list,而是一种叫做dict_keys的类型
result = d1.keys()
print(result)
print(type(result))
# dict_keys和列表类似,可以被遍历,但要注意的是: 他不能通过下标访问元素
for item in result:
print(item)
#print(result[0])
# 借助内置的list函数,可以将dict_keys转换成list
l1 = list(result)
print(l1)
print(type(l1))
# values方法: 获取字典中所有的值
d1 = {'张三': 72,'李四': 60,'王五': 85}
# values方法的返回值类型是: dict_values,它的特点和dict_keys一样
result = d1.values()
print(result)
print(type(result))
# items方法: 获取字典中所有的键值对(每组键值对以元组的形式呈现)
d1 = {'张三': 72,'李四': 60,'王五': 85}
result = d1.items()
print(result)
print(type(result))4. 字典的循环遍历
# 字典不能使用while循环遍历,但可以使用for循环遍历
d1 = {'张三': 72,'李四': 60,'王五': 85}
for key in d1:
print(f'{key}的成绩是{d1[key]}')
for key in d1.keys():
print(f'{key}的成绩是{d1[key]}')12. 数据容器的通用操作
1. list函数: 1. 定义空列表。2.将【可迭代对象】转为列表
res1 = list(range(8))
res2 = list('欢迎来到尚硅谷')
res3 = list({10,20,30,40,50})
res4 = list({'张三': 75,'李四':80})
print(type(res1),res1)
print(type(res2),res2)
print(type(res3),res3)
print(type(res4),res4)2. tuple函数: 1. 定义空元组。2.将【可迭代对象】转为元组
res1 = tuple(range(8))
res2 = tuple('欢迎来到尚硅谷')
res3 = tuple({10,20,30,40,50})
res4 = tuple({'张三': 75,'李四':80})
print(type(res1),res1)
print(type(res2),res2)
print(type(res3),res3)
print(type(res4),res4)3. set函数: 1. 定义空集合。2.将【可迭代对象】转为集合
res1 = set(range(8))
res2 = set('欢迎来到尚硅谷')
res3 = set({10,20,30,40,50})
res4 = set({'张三': 75,'李四':80})
print(type(res1),res1)
print(type(res2),res2)
print(type(res3),res3)
print(type(res4),res4)4. str函数: 1. 定义空字符串。2.将【任意类型】转为字符串
res1 = str(range(8))
res2 = str('欢迎来到尚硅谷')
res3 = str({10,20,30,40,50})
res4 = str({'张三': 75,'李四':80})
print(type(res1),res1)
print(type(res2),res2)
print(type(res3),res3)
print(type(res4),res4)5. str函数: 1. 定义空字典。2.将【可迭代对象】转为字典
备注: 交给dict函数的内容必须是键值对才可以,否则就会报错
res1 = dict({'张三': 72,'李四': 60,'王五': 85})
res2 = dict([('张三', 72), ('李四', 60), ('王五', 85)])
res3 = dict((('张三', 72), ('李四', 60), ('王五', 85)))
print(type(res1),res1)
print(type(res2),res2)
print(type(res3),res3)所有的数据容器,都支持【成员运算符】 in / not in 作用: 判断某个元素是否存在于容器中
hobby = ['抽烟','喝酒','烫头']
nums = (10,20,30,40,50)
message = 'hello,atguigu'
citys = {'北京','上海','广州'}
score = {'张三': 72,'李四': 60,'王五': 85}
print('喝酒' in hobby)
print(20 in nums)
print('atguigu' in message)
print('上海' in citys)
print('李华' in score)小练习
# 练习一: 水果清单
fruits = {
'苹果': 4.5,
'香蕉': 3.2,
'橙子': 5.8,
'草莓': 12.0,
'哈密瓜': 8.8
}
# 需求1:打印所有的水果
for key in fruits:
print(f'{key}:{fruits[key]}')
# 需求2: 找到最贵的水果
key = max(fruits, key=fruits.get)
print(f'最贵的水果是{key},价格是{fruits[key]}')
# 练习二: 学生成绩表
students = [
{
'name': '张三',
'scores': {'语文': 88,'数学': 92,'英语': 95}
},
{
'name': '李四',
'scores': {'语文': 75,'数学': 83,'英语': 80}
},
{
'name': '王五',
'scores': {'语文': 92,'数学': 95,'英语': 88}
},
]
# 需求1: 计算每位学生的平均分
for stu in students:
# 获取当前学生的成绩列表
score_list = stu['scores'].values()
# 计算平均值
avg = sum(score_list) / len(score_list)
print(f"{stu['name']}的平均成绩是: {avg:.1f}")
# 需求2: 找到总分最高的学生
def find_best():
# 记录分数最高的学生
best_students = []
# 记录最高分
best_score = 0
# 循环遍历
for stu in students:
# 获取当前学生的总分
total = sum(stu['scores'].values())
print(total,type(total))
# 当前学生的成绩如果大于best_score,就会更新数据
if total > best_score:
best_students = [stu['name']]
best_score = total
# 当前学生的成绩与最高分相同,就加入列表
elif total == best_score:
best_students.append(stu['name'])
print(f'最高分为{best_score},取得最高分的学生有: {best_students}')
find_best()
# 需求3: 评论内容
comment = '这家奶茶真好喝,环境也不错,就是价格有点贵,好喝好喝好喝!强烈推荐!'
# 需求1: 统计’好喝‘出现次数
print(comment.count('好喝'))
# 需求2: 将字符串中的’贵‘替换为’略高‘
comment2 = comment.replace('贵','略高')
print(comment2)
# 需求3: 是否包含’推荐两个字‘
print('推荐' in comment)46.数据容器总结
47.类
1. 类的定义
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
# 说明: 当一个函数被定义在了类中时,那这个函数就被称为: 方法。
# __init__方法: 初始化方法,主要作用: 给当前正在创建的实例对象添加属性
# __init__方法收到的参数: 当前正在创建的实例对象(self)、其他自定义参数
def __init__(self,name,age,sex):
self.name = name
self.age = age
self.sex = sex2. 创建实例
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
# 说明: 当一个函数被定义在了类中时,那这个函数就被称为: 方法。
# __init__方法: 初始化方法,主要作用: 给当前正在创建的实例对象添加属性
# __init__方法收到的参数: 当前正在创建的实例对象(self)、其他自定义参数
# 当我们以后编写代码去创建Person类实例的时候,Python会自动调用__init__
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
p1 = Person('张三',18,'男')
p2 = Person('李四',22,'女')
# 如果直接打印一个实例的话,我们是看不到实例身上的属性的
# print(p1,'p1')
# print(p2,'p2')
# 通过点语法可以访问或修改实例身上的属性
print(p1.name)
print(p1.age)
print(p1.gender)
print('='*20)
print(p2.name)
print(p2.age)
print(p2.gender)
p1.name = '阿三'
print(p1.name)
# 通过实例.__dict__ 可以查看实例身上的所有属性
print(p1.__dict__)
print(p2.__dict__)
# 实例创建完毕后,依然可以通过 实例.属性名 = 值 去给实例追加属性
p1.address = '北京昌平宏福科技园'
print(p1.__dict__)
# 通过type函数,可以查看某个实例对象,是由哪个类创建出来的
print(type(p1))
print(type(p2))3. 自定义方法
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
# 初始化方法(给实例添加行为)
# speak方法收到的参数是: 调用speak方法的实例对象(self)、其他参数
# speak方法只有一份,保存在Person类身上的,所有Person类的实例对象,都可以调用到speak方法
def speak(self,msg):
print(f'我叫{self.name},年龄是{self.age},性别是{self.gender},我想说: {msg}')
# 验证以下: speak方法是存在Person类身上的
# print(Person.__dict__)
# 创建person类的实例对象
p1 = Person('张三',18,'男')
p2 = Person('李四',22,'女')
# 验证以下Person的实例对象身上是没有speak方法的
print(p1.__dict__)
print(p2.__dict__)
# 所有Person类的实例对象,都可以调用到speak方法
# 当执行p1.speak()的时候,查找speak方法的过程: 1.实例对象自身(p1) => 2.实例的“缔造者”的身上
p1.speak('好好学习')
p2.speak('天天向上')
# 验证一下上述的查找过程
def speak():
print('巴拉巴拉巴拉')
p1.speak = speak
print(Person.__dict__)
print(p1.__dict__)
print(p2.__dict__)
p1.speak()4. 实例属性
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
def __init__(self,name,age,gender):
# 通过【实例.属性名 = 值】给实例添加的属性,就叫实例属性
# 实例属性只能通过实例访问,不能通过类访问
# 每个实例都有自己【独一份的】实例属性,各个实例之间是互不干扰的
self.name = name
self.age = age
self.gender = gender
# 创建person类的实例对象
p1 = Person('张三',18,'男')
p2 = Person('李四',22,'女')
# 实例属性只能通过实例访问,不能通过类访问
# print(Person.name)
# print(p1.name)5. 类属性
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
# max_age、planet 他们都是类属性,类属性是保存在类身上的
# 类属性可以通过类访问,也可以通过实例访问
# 类属性通常用于保存:公共数据
max_age = 120
planet = '地球'
# 初始化方法
def __init__(self,name,age,gender):
# 给实例添加属性
self.name = name
self.age = age
self.gender = gender
# 验证一下: 类属性是保存在类身上的
print(Person.__dict__)
# 创建person类的实例对象
p1 = Person('张三',18,'男')
p2 = Person('李四',22,'女')
# 验证一下: 实例身上是没有类属性的
print(p1.__dict__)
print(p2.__dict__)
# 验证一下: 类属性可以通过类访问,也可以通过实例访问
print(Person.max_age)
print(p1.max_age)
print(p2.max_age)6. 实例方法
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
# 下面的speak方法、run方法,都保存在类身上,但他们主要是供实例调用,所以他们都叫:实例方法
# 自定义方法(给实例添加行为)
def speak(self,msg):
print(f'我叫{self.name},年龄是{self.age},性别是{self.gender},我想说: {msg}')
# 自定义方法(给实例添加行为)
def run(self, distance):
print(f'我叫{self.name}疯狂的奔跑了{distance}米')
# 通过实例调用实例方法
p1 = Person('张三',18,'男')
p2 = Person('李四',22,'女')
p1.speak('你好')
p2.run(300)
# 通过类调用实例方法
Person.run(p1,100)7. 类方法
from datetime import datetime
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
# 类属性
max_age = 120
planet = '地球'
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
# 下面的speak方法、run方法,都保存在类身上,但他们主要是供实例调用,所以他们都叫:实例方法
# 自定义方法(给实例添加行为)
def speak(self,msg):
print(f'我叫{self.name},年龄是{self.age},性别是{self.gender},我想说: {msg}')
# 自定义方法(给实例添加行为)
def run(self, distance):
print(f'我叫{self.name}疯狂的奔跑了{distance}米')
# 使用 @classmethod 装饰过去的方法,就叫:类方法,类方法保存在类身上
# 类方法收到的参数: 当前类本身(cls)、自定义的参数
# 因为收到了cls参数,所以类方法中是可以访问类属性的
# 类方法通常用于实现: 与类相关的逻辑,例如: 操作类级别的信息、一些工厂方法
@classmethod
def change_planet(cls,value):
cls.planet = value
@classmethod
def create(cls,info_str):
# 从info——str中获取到有效信息
name,year,gender = info_str.split('-')
# 获取当前年份
current_year = datetime.now().year
# 计算年龄
age = current_year - int(year)
# 创建Person类的实例对象
return cls(name,age,gender)
# 验证一下: 类方法保存在类身上的
print(Person.__dict__)
# 类方法需要通过类调用
# Person.test1(900)
# Person.test2(900)
Person.change_planet('月球')
# 通过实例调用实例方法
p1 = Person('张三',18,'男')
p2 = Person('李四',22,'女')
# 验证一下: 类方法身上的属性已经被修改了
print(p1.planet)
print(p2.planet)
# 测试一下类方法 -- create8. 静态方法
from datetime import datetime
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
# 静态方法
# 使用@staticmethod 装饰过的方法,就叫:静态方法,静态方法也是保存在类身上的
# 静态方法只是单纯的定义在类中,它不会收到:self、cls参数,它收到的参数都是自定义参数
# 由于静态方法没有收到:self、cls参数,所以其内部不会访问任何类和实例相关的内容
# 静态方法通常用于定义: 与类相关的工具方法
@staticmethod
def is_adult(year):
# 获取当前的年份
current_year = datetime.now().year
# 计算年龄
age= current_year - year
return age >= 18
@staticmethod
def mask_idcard(idcard):
return idcard[:6] + '*********' + idcard[-4:]
# 验证一下: 静态方法也是保存在类身上的
# print(Person.__dict__)
# 静态方法需要通过类去调用
# result = Person.is_adult(20)
# print(result)
# result2 = Person.mask_idcard('1402252665896485275687')
# print(result2)9. 继承
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
# 类属性
max_age = 120
planet = '地球'
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
def speak(self,msg):
print(f'我叫{self.name},年龄是{self.age},性别是{self.gender},我想说: {msg}')
# 定义一个Student类(字类、派生类),继承自Person类(父类,超类、基类)
class Student(Person):
def __init__(self, name, age, gender, stu_id, grade):
# 方式一
# super().__init__(name, age, gender)
# 方式二
Person.__init__(self,name,age,gender)
# 子类独有的属性,需要自己手动完成初始化
self.stu_id = stu_id
self.grade = grade
def study(self):
print(f'我叫{self.name},我在努力的学习,争取做到{self.grade}年级的第一名')
# 创建student类的实例对象
s1 = Student('李华',16,'男','2025001','初二')
print(s1.__dict__)
print(type(s1))
# def speak(data):
# print("hello")
# s1.speak = speak
# 查找speak方法的过程: 1.实例自身(s1) => 2.Student类 => 3.Person类
s1.speak('你好')
s1.study()10. 方法重写
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
# 类属性
max_age = 120
planet = '地球'
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
def speak(self,msg):
print(f'我叫{self.name},年龄是{self.age},性别是{self.gender},我想说: {msg}')
# 定义一个Student类(字类、派生类),继承自Person类(父类,超类、基类)
class Student(Person):
def __init__(self,name,age,gender,stu_id,grade):
super().__init__(name,age,gender)
self.stu_id = stu_id
self.grade = grade
# 方法重写: 当子类中定义了一个与父类中相同的方法,那么子类中的方法就会"覆盖"父类的方法
def speak(self, msg):
super().speak(msg)
print(f'我是学生,我的学号是{self.stu_id},我正在读{self.grade},我想说: {msg}')
s1 = Student('李华',12,'男','2025001','初二')
s1.speak('好好学习')11. 两个常用的方法
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
# 类属性
max_age = 120
planet = '地球'
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
# 定义一个Student类(字类、派生类),继承自Person类(父类,超类、基类)
class Student(Person):
def __init__(self,name,age,gender,stu_id,grade):
super().__init__(name,age,gender)
self.stu_id = stu_id
self.grade = grade
p1 = Person('张三',18,'男')
s1 = Student('李华',12,'男','2025001','初二')
# 方法1: isinstance(instance,Class), 作用: 判断某个对象是否为指定类或其子类的实例
print(isinstance(s1,Student))
print(isinstance(p1,Person))
print(isinstance(s1,Person))
print(isinstance(p1,Student))
# 方法2: issubclass(Class1,Class2),作用: 判断某个类是否是另一个类的子类
print(issubclass(Student,Person))
print(issubclass(Person,Student))12. 多重继承
# 概念: 多重继承指一个类同时继承多个父类,从而拥有多个父类的属性和方法
# 举例: 就像孩子不仅继承爸爸的长相,也能继承妈妈的性格
# 定义一个Person类(类名通常使用: 大驼峰写法)
class Person:
def __init__(self,name,age,gender):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name
self.age = age
self.gender = gender
def speak(self):
print(f'我叫{self.name},年龄是{self.age},性别是{self.gender}')
class Worker:
def __init__(self,company):
self.company = company
def do_work(self):
print(f'我在{self.company}做兼职')
class Student(Person, Worker):
def __init__(self,name,age,gender,company,stu_id,grade):
# super().__init__(name,age,gender)
# super().__init__(company)
Person.__init__(self,name,age,gender)
Worker.__init__(self,company)
self.stu_id = stu_id
self.grade = grade
def study(self):
print(f'我在努力的学习,争取做{self.grade}年级的第一名')
s1 = Student('张三',18,'男','麦当劳','2025001','初二')
print(s1.__dict__)
s1.speak()
s1.do_work()
s1.study()
# 类的__mro__属性: 用于记录属性和方法的查找顺序
# 通过实例去查找属性或方法时,会先在实例身上去查找,如果没有,就按找__mro__记录的顺序去查找
print(Student.__mro__)13. 三种权限
class Person:
def __init__(self,name,age,idcard):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name # 公有属性: 当前类中、子类中、类外部,都可以访问
self._age = age # 受保护的属性:当前类中、子类中,都可以访问
self.__idcard = idcard # 私有属性: 仅在当前类中访问
def speak(self):
print(f'我叫: {self.name},年龄: {self._age},身份证: {self.__idcard}')
class Student(Person):
def hello(self):
print(f'我是学生({self.name}-{self._age})')
s1 = Student('张三',18,'110101199001011234')
s1.hello()
p1 = Person('张三',18,'110101199001011234')
# print(p1.name)
# 在类的外部,如果强制访问【受保护的属性】也能访问到,但十分不推荐!
print(p1._age)
# 在类的外部,如果强制访问【私有属性】不能访问到,而且会报错!
# print(p1.__idcard)
# Python底层是通过重命名的方式,实现私有属性的
print(p1.__dict__)14. getter和setter
class Person:
def __init__(self,name,age,idcard):
# 给实例添加属性(语法为: self.属性名=属性值)
self.name = name # 公有属性: 当前类中、子类中、类外部,都可以访问
self._age = age # 受保护的属性:当前类中、子类中,都可以访问
self.__idcard = idcard # 私有属性: 仅在当前类中访问
# 注册age属性的getter方法,当访问Person实例的age属性时,下面的age方法就会被自动调用
@property
def age(self):
return self._age
# 注册age属性的setter方法,当访问Person实例的age属性时,下面的age方法就会被自动调用
@age.setter
def age(self,value):
self._age = value
@property
def idcard(self):
return self.__idcard[:6] + '*********' + self.__idcard[-4:]
@idcard.setter
def idcard(self,value):
self.__idcard = value
p1 = Person('张三',18,'11010119901011246')
print(p1.name)
p1.age = 99
print(p1.age)
print(p1.idcard)15. 魔法方法
# 概念: 以 __xx__ 命名的特殊方法(双下划线开头和结尾)
# 特点: 不需要我们手动调,我们只要 准备好这些方法,Python会在特定场景下,去自动调用。
class Person:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
# 当执行print(Person的实例对象) 或 str(Person的实例对象) 时调用
def __str__(self):
return f'{self.name}-{self.age}-{self.gender}'
# 当执行len(Person的实例对象)或str(Person的实例对象)时调用
def __len__(self):
return len(p1.__dict__)
# 当执行 Person实例对象1 < Person实例对象2 时调用
def __lt__(self,other):
return self.age < other.age
# 当执行 Person实例对象1 > Person实例对象2 时调用
def __gt__(self, other):
return self.age > other.age
# 当执行 Person实例对象1 = Person实例对象2 时调用
def __eq__(self, other):
return len(self.__dict__) == len(other.__dict__)
# 当访问Person实例对象身上不存在的属性时调用
def __getattr__(self, item):
return f"您访问的{item}属性不存在"
p1 = Person('张三',22,'男')
# p2 = Person('张三',22,'男')
p2 = Person('李四',19,'女')
# print(p1)
# print(p2)
# res = len(p1)
# print(res)
# print(p1 < p2)
# print(p1 > p2)
# print(p1 == p2)
print(p1.address)16. object类
# Python中,所有的类都继承了 object类,即: object类是所有类的顶层父亲。
class Person:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
# 验证一下,所有的类继承了object类
# print(issubclass(Person,object))
# print(issubclass(int,object))
# print(issubclass(str,object))
# print(issubclass(list,object))
# print(issubclass(bool,object))
# print(issubclass(tuple,object))
# 因为 object 是所有类的父亲,所以 Python 中的所有对象,都间接是 object 类的实例。
# p1 = Person('张三',18,'男')
# print(isinstance(p1,object))
# print(isinstance(100,object))
# print(isinstance('hello',object))
# print(isinstance(True,object))
# print(isinstance(None,object))
# print(isinstance([10,20,30],object))
# print(isinstance({'吃饭','睡觉'},object))
# 所有对象都继承了object类所提供的: 各种属性和方法,从而保证了每个对象都具备统一的基本能力
# for key in object.__dict__:
# print(key)
p1 = Person('张三',18,'男')
print(p1.__dict__) # 对象身上自己的东西
print(dir(p1)) # 对象可以访问到的东西
print(p1.__str__())17. 标准多态
# 多态的概念: 同一个方法名,在不同的对象上调用时,能呈现出不同的行为。
# Python中支持: 标准多态、鸭子多态
class Animal:
def speak(self):
print('动物正在发出声音')
class Dog(Animal):
def speak(self):
print('汪汪汪')
class Cat(Animal):
def speak(self):
print('喵喵喵!')
class Pig:
def speak(self):
print('哼哼哼!')
def make_sound(animal:Animal): # 类型注解
animal.speak()
# 创建实例对象
a1 = Animal()
d1 = Dog()
c1 = Cat()
p1 = Pig()
make_sound(a1)
make_sound(d1)
make_sound(c1)
make_sound(p1) # 该行代码在其他语言中就已经报错了,在Python中不推荐18. 鸭子多态
# 核心理念: 如果一个东西看起来像鸭子,叫起来也像鸭子,那它就是鸭子。
# 鸭子类型是一种编程风格,它不检查对象的类型,只关注对象能否"做某件事"(是否有对应的方法)
# 鸭子多态
class Dog:
def speak(self):
print('汪汪汪')
class Cat:
def speak(self):
print('喵喵喵!')
class Pig:
def speak(self):
print('哼哼哼!')
class Fish:
def speak(self):
print('咕噜噜!')
class Computer:
def speak(self):
print('滋滋滋!')
def make_sound(animal):
animal.speak()
# 创建实例对象
d1 = Dog()
c1 = Cat()
p1 = Pig()
f1 = Fish()
com = Computer()
print(make_sound(d1))
print(make_sound(c1))
print(make_sound(p1))
print(make_sound(f1))
print(make_sound(com))19. 抽象类
【抽象类】是一种不能直接实例化的类,它通常作为"规范",让子类去继承,并实现其中定义的【抽象方法】
from abc import ABC,abstractmethod
# 【抽象类】是一种不能直接实例化的类,它通常作为"规范",让子类去继承,并实现其中定义的【抽象方法】
# MustRun类一旦继承了ABC类,那么MustRun类就是抽象类
class MustRun(ABC):
@abstractmethod
def run(self):
pass
class Person(MustRun):
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def run(self):
print(f'我叫{self.name},我在努力的奔跑')
p1 = Person('张三',18,'男')
p1.run()20. 小练习
from datetime import datetime
class Person:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
class Student(Person):
count = 0
def __init__(self, name, age, gender):
super().__init__(name,age,gender)
Student.count += 1
self.stu_id = f'{datetime.now().year}{Student.count:03d}'
self.scores = {}
# 给当前学生添加成绩
def add_score(self,subject,score):
self.scores[subject] = score
# 计算平均分
def calcu_avg(self):
if self.scores:
return sum(self.scores.values()) / len(self.scores)
else:
return 0
# 魔法方法
def __str__(self):
return f'{self.name}({self.age}-{self.gender}),成绩: {self.scores},平均分: {self.calcu_avg():.1f}'
# s1 = Student('张三',18,'男')
# s1.add_score('数学',90)
# s1.add_score('语文',80)
# s1.add_score('英语',70)
# print(s1.calcu_avg())
# # print(s1.__dict__)
# print(s1)
class Manager:
def __init__(self):
self.stu_list = []
# 添加学生
def add_student(self):
name = input('请输入姓名:')
age = int(input('请输入年龄:'))
gender = input('请输入性别:')
stu = Student(name,age,gender)
self.stu_list.append(stu)
print(f"添加成功!学号是: {stu.stu_id}")
# 删除学生
def del_student(self):
sid = input('请输入学号:')
target = None
for stu in self.stu_list:
if stu.stu_id == sid:
target = stu
if target:
self.stu_list.remove(target)
print("删除成功")
else:
print("学号有误,删除失败!")
# 展示所有学生
def show_all_student(self):
if self.stu_list:
for stu in self.stu_list:
print(stu)
else:
print('暂无学生!')
# 给指定学生设置成绩
def set_score(self):
sid = input('请输入学号:')
for stu in self.stu_list:
if stu.stu_id == sid:
score_str = input('请输入成绩(学科-分数,学科-分数)')
score_list = score_str.replace(',',',').split(',')
for item in score_list:
subject,score = item.split('-')
subject = subject.strip()
score = float(score.strip())
stu.add_score(subject,score)
print('添加成功!')
return
print('学号有误!')
# 提供主菜单
def run(self):
while True:
print('********学生管理********')
print('1.添加学生')
print('2.删除学生')
print('3.查看所有学生')
print('4.录入成绩')
print('5.退出')
choice = input('请输入您需要进行的操作: ')
if choice == '1' :
self.add_student()
elif choice == '2':
self.del_student()
elif choice == '3':
self.show_all_student()
elif choice == '4':
self.set_score()
elif choice == '5':
print('再见!')
break
else:
print('输入有误!')
m1 = Manager()
m1.run()48. 重新认识函数
1. 函数也是对象
# 1. 函数也是对象
a1 = 100 #int类的实例对象
a2 = 'hello' #str类的实例对象
a3 = [10,20,30] #list类的实例对象
print(type(a1))
print(type(a2))
print(type(a3))
def welcome(): #function类的实例对象
print('你好啊')
print(type(welcome))2.函数可以动态添加属性
# 2.函数可以动态添加属性
def welcome():
print('你好啊')
welcome.desc = '这是一个打招呼的函数'
welcome.version = '1.0'
print(welcome.desc)
print(welcome.version)3. 函数可以赋值给变量
# 3. 函数可以赋值给变量
def welcome():
print('你好啊')
welcome.desc = '这是一个打招呼的函数'
welcome.version = '1.0'
say_hello = welcome
say_hello()
print(say_hello.desc)
print(say_hello.version)4. 可变参数 vs 不可变参数
# 4. 可变参数 vs 不可变参数
# 不可变参数
a = 666
def welcome(data):
print('data修改前',data,id(data))
data = 888
print('data修改后',data,id(data))
print(data)
print('data修改前', a, id(a))
welcome(a)
print('data修改后', a, id(a))
print(a)
# 可变参数
a = [10,20,30]
def welcome(data):
print('data修改前',data,id(data))
data[2] = 99
print('data修改后',data,id(data))
print('函数调用前',a,id(a))
welcome(a)
print('函数调用后',a,id(a))5. 函数也可以作为参数
def welcome():
print('你好啊')
def caller(f):
print('caller函数调用了')
f()
caller(welcome)6. 函数也可以作为返回值
def welcome():
print('你好啊')
def show_msg(msg):
print(msg)
return show_msg
result = welcome()
result('尚硅谷')49. 多返回值_参数的打包与解包
# 一、函数的多返回值
def calculate(x,y):
res1 = x + y
res2 = x - y
return res1,res2
# result = calculate(30,10)
# print(result)
r1,r2 = calculate(30,10)
print(r1)
print(r2)
# 二、参数的打包与解包
# 1. 打包结束参数:
# *args: 打包所有的位置参数(会形成一个元组)
# *kwargs: 打包所有的关键字参数(会形成一个字典)
def show_info(*args,**kwargs):
print(args)
print(kwargs)
show_info(10,20,30,name='张三',age=18,gender='男')
# 2. 解包传递参数
# *变量名: 将元组拆解成一个一个独立的位置参数
# **变量名: 将字典拆解一个一个 key=value形式的关键字参数
def show_info(num1,num2,num3,name,age,gender):
print(num1,num2,num3)
print(name,age,gender)
nums = (10,20,30)
person = {'name': '张三','age': 18,'gender':'男'}
# show_info(10,20,30,'张三',18,'男')
show_info(*nums,**person)
# 3. 打包接收参数 和 解包传递参数 一起使用
def show_info(*args,**kwargs):
print(args)
print(kwargs)
nums = (10,20,30)
person = {'name': '张三','age': 18,'gender':'男'}
show_info(*nums,**person)50. 高阶函数
高阶函数: 当一个函数的【参数是函数】或者【返回值是函数】那该函数就是【高阶函数】
高阶函数的意义:
- 代码复用性高: 可以把行为"独立出去",传入不同函数实现不同逻辑
- 能让函数更灵活,更通用
- 高阶函数是: 装饰器、闭包的基础
# 高阶函数: 当一个函数的【参数是函数】或者【返回值是函数】那该函数就是【高阶函数】
# 高阶函数的意义:
# 1. 代码复用性高: 可以把行为"独立出去",传入不同函数实现不同逻辑
# 2. 能让函数更灵活,更通用
# 3. 高阶函数是: 装饰器、闭包的基础
def info(msg):
return '[提示]:' + msg
def warn(msg):
return '[警告]:' + msg
def error(msg):
return '[错误]:' + msg
def log(func,text):
print(func(text))
log(info,'文件保存成功!')
log(warn,'磁盘空间不足!')
log(error,'该用户不存在!')51. 条件表达式
表达式: 执行后能得到值的代码,就是表达式(表达式最终会形成一个值,可以写在任何需要值得地方)
# 表达式: 执行后能得到值的代码,就是表达式(表达式最终会形成一个值,可以写在任何需要值得地方)
# a1 = 3 + 5
# a2 = 'abc' * 3
# a3 = 5 > 3
# a4 = 'y' in 'python'
# a5 = len('hello')
# 条件表达式: 根据条件得真假,在两个结果中二选一的表达式(又称: 三元表达式、三目运算符)
age = 21
# 传统的if-else去写:
# if age >= 18:
# text = '成年'
# else:
# text = '未成年'
#
# print(text)
# 条件表达式去写: 值1 if条件 else 值2
text = '成年' if age >=18 else '未成年'
print(text)
# 条件表达式的使用场景: 简单的二选一场景
rain = True
eat = '外卖' if rain else '出去吃'
print(eat)
is_vip = False
disscount = 0.8 if is_vip else 1.0
print(disscount)
is_login = False
msg = '欢迎回来!' if is_login else print('哈哈哈')
print(msg)52. 匿名函数
概念: 所谓【匿名函数】,就是没有名字的函数,它无需使用def关键字去定义。
语法: Python中使用lambda关键字来定义【匿名函数】,格式为: lambda参数: 表达式
使用场景: 当一个函数只用一次、只做一点点小事,使用匿名函数会更简洁
注意点:
- 只能写一行,不能写多行代码。
- 不能写代码块(if、for、while)
- 冒号右边必须是表达式,且只能写一个表达式。
- 表达式结果自动作为返回值。
# 概念: 所谓【匿名函数】,就是没有名字的函数,它无需使用def关键字去定义。
# 语法: Python中使用lambda关键字来定义【匿名函数】,格式为: lambda参数: 表达式
# 使用场景: 当一个函数只用一次、只做一点点小事,使用匿名函数会更简洁
# 使用普通函数实现计算效果
def add(x,y):
return x + y
def sub(x,y):
return x - y
def calculate(func,a,b):
print(f'计算结果为: {func(a,b)}')
calculate(add,30,10)
calculate(sub,30,10)
# 匿名函数
add1 = lambda x,y: x + y
sub = lambda x,y: x - y
add2 = lambda x: x + x
add3 = lambda : '我是add3函数'
result = add1(30,10)
result2 = sub(30,10)
result3 = add2(30)
result4 = add3()
print(result)
print(result2)
print(result3)
print(result4)
# 使用匿名函数实现计算效果
def calculate(func,a,b):
print(f'计算结果为: {func(a,b)}')
calculate(lambda x,y: x + y,30,10)
calculate(lambda x,y: x - y,30,10)
# 注意点:
# 1. 只能写一行,不能写多行代码。
# 2. 不能写代码块(if、for、while)
# 3. 冒号右边必须是表达式,且只能写一个表达式。
# 1. 表达式结果自动作为返回值。53. 几个数据处理函数
map函数
map函数: 对一组数据中的每一个元素,统一执行某种操作(加功),并生成一组新数据。
语法格式: map(操作函数,可迭代对象)
注意点:
- 延迟执行: map 不会立刻计算,只有在"需要结果"时才执行计算。
- 返回的是迭代器对象,且一旦遍历完成,就会被“耗尽”。
- map不会影响元素数量
# map函数: 对一组数据中的每一个元素,统一执行某种操作(加功),并生成一组新数据。
# 语法格式: map(操作函数,可迭代对象)
# 统一数据处理
nums = [10,20,30,40]
def double(x):
return x * 2
# map函数的返回值是一个迭代器对象,需要我们自己去手动遍历,或者手动类型转换
result = map(lambda x: x * 2,nums)
print(list(result))
print(nums)
# 字符串转换
names = ('python','java','js')
result = map(lambda x: x.upper(),names)
print(tuple(result))
print(names)
# str1 = 'hello'
# result = str1.upper()
# print(result)
# 类型转换
str_number = {'1','2','3'}
result = map(int,str_number)
print(set(result))
print(str_number)
# 注意点:
# 1. 延迟执行: map 不会立刻计算,只有在"需要结果"时才执行计算。
# 2. 返回的是迭代器对象,且一旦遍历完成,就会被“耗尽”。
# 3. map不会影响元素数量filter函数
filter函数: 从一组数据中,筛选出符合条件的元素(过滤),并组成一组新数据。
语法格式: filter(过滤函数,可迭代对象)
注意点:
- 延迟执行: filter不会立刻筛选,只有在“需要结果”时才执行。
- 返回的是迭代器对象,且一旦遍历完成就会被“耗尽”
- filter可能会影响元素数量
# filter函数: 从一组数据中,筛选出符合条件的元素(过滤),并组成一组新数据。
# 语法格式: filter(过滤函数,可迭代对象)
# 筛选数值
nums = [10,20,30,40,50]
result = filter(lambda n: n > 30, nums)
print(list(result))sorted函数
sorted函数: 对一组数据进行排序,返回一组新数据
语法格式: sorted(可迭代对象,key=xxx,reverse=xxx)
# sorted函数: 对一组数据进行排序,返回一组新数据
# 语法格式: sorted(可迭代对象,key=xxx,reverse=xxx)
# 数字排序
nums = [30,40,20,10]
result = sorted(nums,reverse=True)
print(result)
# 按照字符串的长度去排序
names = ['python','sql','java']
result = sorted(names,key=len,reverse=True)
print(result)
# 根据字典中的某个字段进行排序
persons = [
{'name': '张三','age':15,'gender': '男'},
{'name': '李四','age':17,'gender': '男'},
{'name': '王五','age':19,'gender': '男'},
{'name': '李华','age':20,'gender': '男'},
{'name': '赵六','age':18,'gender': '男'},
{'name': '孙七','age':16,'gender': '男'},
]
result = sorted(persons,key=lambda n: n['age'])
print(result)
# 我们之前将的max函数、min函数,也可以传递key参数,用于设置筛选依据
result1 = max(persons,key=lambda n: n['age'])
result2 = min(persons,key=lambda n: n['age'])
print(result1)
print(result2)reduce函数
reduce函数: 将一组数据不断'合并',最终归并成一个结果。
语法格式: reduce(合并函数,可迭代对象,初始值)
备注: reduce函数需要从functools模块中引入才能使用
# reduce函数: 将一组数据不断'合并',最终归并成一个结果。
# 语法格式: reduce(合并函数,可迭代对象,初始值)
# 备注: reduce函数需要从functools模块中引入才能使用
# 从functools模块中引入reduce
from functools import reduce
# 数值统计
nums = [1,2,3,4,5]
def count(a,b):
return a + b
result = reduce(count,nums,0)
print(result)54. 列表推导式
# 列表推导式: 用一条简洁语句,从可迭代对象中,生成新列表的语法结构
# 备注: 列表推导式本质上是对for循环 + append()的一种简写形式。
# 语法格式: [表达式 for 变量 in 可迭代对象]
# 需求:让列表中每个元素,都变为原来的2倍,得到是一个新的列表
# 方式一: 用map函数
nums = [10,20,30,40]
result = list(map(lambda n: n * 2,nums))
print(result)
# 方式二: 用map函数
nums = [10,20,30,40]
result = []
for item in nums:
result.append(item * 2)
print(result)
# 方式三: 用列表推导式
nums = [10,20,30,40]
result = [n*2 for n in nums]
print(result)
# 带条件的列表推导式
nums = [10,20,30,40]
result = [n * 2 for n in nums if n > 20]
print(result)
# 字典推导式
names = ['张三','李四','王五']
scores = [60,70,80]
result = { names[i]:scores[i] for i in range(len(names)) }
print(result)
# 集合推导式
names = ['张三','李四','王五']
result = {n + '!' for n in names}
print(result)
# Python中没有元组推导式,下面这种写法叫生成器
names = ['张三','李四','王五']
result = (n + '!' for n in names)
print(result)55. 深拷贝与浅拷贝
浅拷贝
创建一个新的外层容器,但内部元素仍然引用原来的对象。
浅拷贝存在的问题:
嵌套数据仍然是共享的,修改嵌套数据会相互影响
深拷贝
创建一个新的外层容器,并对其内部所有的可变对象进行递归复制
备注:
1.深拷贝可以彻底消除数据之间的相互影响
2.深拷贝遇到【不可变对象】不会复制,会直接引用
56.四种作用域
局部作用域
在函数内部定义的变量,只能在函数内部使用
全局作用域
在函数外部定义的变量,可以在所有地方使用
内置作用域
Python内置的名称空间,可以直接调用。例如: print()、len()等
闭包作用域
嵌套函数中,内层函数可以访问外层函数的参数和变量,但反过来不行
# 作用域: 指的是变量的有效范围
# 局部作用域
def test():
x = 100
print(x)
test()
# 全局作用域
x = 200
def test():
print(x)
test()
# 内置作用域
import builtins
print(dir(builtins))
# 闭包作用域
def outer_func():
a = 100
b = 200
def inner_func():
print(a,b)
return inner_func
result = outer_func()
result()57. 闭包
什么是闭包? --- 闭包 = 内层函数 + 被内层函数所引用的外层变量
闭包产生的条件:
- 要有函数嵌套
- 在【内层函数】中,要访问【外层函数】的变量
- 并且【外层函数】要返回【内层函数】。---只有返回了内层函数,闭包才能“活下来”
闭包的优点:
- 可以记住状态: 不用全局变量,也不用写类,就能在多次调用之间保存数据。
- 可以做"配置过的函数": 先传一部分参数,把环境固定住,得到一个定制版函数。
- 可以实现简单的"数据隐藏": 外层变量对外不可见,只能通过内层函数访问
- 是装饰器(decorator)等高级用法的基础
闭包的缺点:
- 理解成本较高: 对初学者不太友好,滥用会让代码难读。
- 如果闭包里引用了很大的对象,又长期不释放,可能会增加内存占用。
- 很多场景下,其实用【类+实例属性】会更清晰,闭包不一定是最优解
# 前置知识一:
# 1. 每次调用函数时,Python都会为函数创建一个新的局部作用域
# 2. 函数执行完毕后,这个局部作用域会被销毁,其中的局部变量也会随之被释放
def outer():
num = 10
num += 1
print(num)
outer()
outer()
outer()
# 前置知识二:
# 1. 在Python中,【内置函数】可以访问其【外层函数】作用域中的变量
# 2. 访问外层函数变量无需使用nonlocall但修改外层变量时要使用nonlocal
def outer():
num = 10
def inner():
nonlocal num
num = 12
print('局部作用域中的num:',num)
inner()
print('全局作用域中的num:',num)
outer()
# 什么是闭包? --- 闭包 = 内层函数 + 被内层函数所引用的外层变量
# 闭包产生的条件:
# 1.要有函数嵌套
# 2.在【内层函数】中,要访问【外层函数】的变量
# 3.并且【外层函数】要返回【内层函数】。---只有返回了内层函数,闭包才能“活下来”
def outer():
num = 10
print(hex(id(num)))
def inner():
nonlocal num
num += 1
print(num)
print(inner.__closure__)
return inner
f = outer()
f()
# 结论:
# 1. outer函数中,被inner所使用到的那些变量,会被封存到【闭包单元(cell)】中
# 2. 这些cell会组成一个 __closure__元组,最终放在了inner函数身上。
# 打印__closure__元组
# print(f.__closure__) # 闭包单元
# 打印 __closure__元组中的某一项
# print(f.__closure__[0])
# 打印 __closure__元组中的某一项的具体值
# print(f.__closure__[0].cell_contents)
# 注意点
# 1. 调用n次外层函数,就会得到n个不用的闭包,并且这些闭包之间互补影响
def outer():
num = 10
print(hex(id(num)))
def inner():
nonlocal num
num += 1
print(num)
return inner
f1 = outer()
f1()
f1()
f1()
print('*********')
f2 = outer()
f2()
# 2. 内层函数中用到的外层变量是可变对象,多个闭包之间依然互不影响
def outer():
nums = []
def inner(value):
nonlocal nums
nums.append(value)
print(nums)
return inner
f1 = outer()
f1(10)
f1(20)
f1(30)
print('************')
f2 = outer()
f2(666)
# 闭包的优点:
# 1. 可以记住状态: 不用全局变量,也不用写类,就能在多次调用之间保存数据。
# 2. 可以做"配置过的函数": 先传一部分参数,把环境固定住,得到一个定制版函数。
# 3. 可以实现简单的"数据隐藏": 外层变量对外不可见,只能通过内层函数访问
# 4. 是装饰器(decorator)等高级用法的基础
def beauty(char,n):
def show_msg(msg):
print(char * n + msg + char * n)
return show_msg
show1 = beauty('*',3)
show1("你好啊")
show1("尚硅谷")
show2 = beauty('@',5)
show2('你好啊')
show2("尚硅谷")
# 闭包的缺点:
# 1. 理解成本较高: 对初学者不太友好,滥用会让代码难读。
# 2. 如果闭包里引用了很大的对象,又长期不释放,可能会增加内存占用。
# 3. 很多场景下,其实用【类+实例属性】会更清晰,闭包不一定是最优解
class Beauty:
def __init__(self,char,n):
self.char = char
self.n = n
def show_msg(self,msg):
print(self.char * self.n + msg + self.char * self.n)
b1 = Beauty('*',3)
b1.show_msg('你好啊')
b1.show_msg('尚硅谷')58. 函数装饰器
装饰器:
- 装饰器是一种【可调用对象】(通常是函数),它能接收一个函数作为参数,并且会返回一个新函数。
- 装饰器可以在不修改原函数代码的前提下,增强或改变原函数的功能。 实际应用: 在不改变原函数的前提下,给函数统一加上: 日志、计时、校验、缓存 等功能
关键点:
- 接收被装饰的函数、同时返回新函数(wrapper)
- 装饰器"吐出来"的是wrapper函数,以后别人调用的也是wrapper 函数。
- 为了保证参数的兼容性,wrapper 函数要通过*args 和 **kwargs 接收参数
- wrapper 函数中主要做的是: 调用原函数(被装饰的函数)、执行其他逻辑,但要记得将原函数的返回值 return出去。
# 装饰器:
# 1. 装饰器是一种【可调用对象】(通常是函数),它能接收一个函数作为参数,并且会返回一个新函数。
# 2. 装饰器可以在不修改原函数代码的前提下,增强或改变原函数的功能。
# 实际应用: 在不改变原函数的前提下,给函数统一加上: 日志、计时、校验、缓存 等功能
# 关键点:
# 1.接收被装饰的函数、同时返回新函数(wrapper)
# 2.装饰器"吐出来"的是wrapper函数,以后别人调用的也是wrapper 函数。
# 3.为了保证参数的兼容性,wrapper 函数要通过*args 和 **kwargs 接收参数
# 4. wrapper 函数中主要做的是: 调用原函数(被装饰的函数)、执行其他逻辑,但要记得将原函数的返回值 return出去。
def say_hello(func):
def wrapper(*args,**kwargs):
# ***********
print('****你好啊****')
return func(*args,**kwargs)
return wrapper
@say_hello
def add(x,y,z):
res = x + y + z
print(f'{x}和{y}和{z}相加的结果是{res}')
return res
# 正常调用add函数
result = add(10,20)
print(result)
# 需求: 在不修改add函数的前提下,给add函数增加一些额外的功能,例如: 计算前先打印一句欢迎语
# 实现方案: 使用装饰器
add = say_hello(add)
result = add(10,20)
print(result)
# 进阶: 带参数的装饰器
def say_hello(msg):
def outer(func):
def wrapper(*args,**kwargs):
# ***********
print(f'****你好,我要开始{msg}计算了****')
return func(*args,**kwargs)
return wrapper
return outer
#
@say_hello('加法')
def add(x,y,z):
res = x + y + z
print(f'{x}和{y}和{z}相加的结果是{res}')
return res
@say_hello('减法')
def sub(x,y):
res = x - y
print(f'{x}和{y}相减的结果是{res}')
return res
# # 正常调用add函数
result1 = add(10,20,30)
print(result1)
result2 = sub(20,10)
print(result2)
# 进阶: 多个装饰器一起使用
def test1(func):
print('我是test1装饰器')
def wrapper(*args,**kwargs):
print('我是test1追加的逻辑')
return func(*args,**kwargs)
return wrapper
def test2(func):
print('我是test2装饰器')
def wrapper(*args,**kwargs):
print('我是test2追加的逻辑')
return func(*args,**kwargs)
return wrapper
@test1
@test2
def add(x,y):
res = x + y
print(f'{x}和{y}相加的结果是{res}')
return res
result = add(10,20)59. 类装饰器
类装饰器:
- 包含__call__方法的类,就是类装饰器
- 像调用函数一样,去调用类装饰器的实例对象,就会触发 __call__方法的调用。
- __call__方法通常接受一个函数作为参数,并且会返回一个新函数。
# 类装饰器:
# 1.包含__call__方法的类,就是类装饰器
# 2. 像调用函数一样,去调用类装饰器的实例对象,就会触发 __call__方法的调用。
# 3. __call__方法通常接受一个函数作为参数,并且会返回一个新函数。
class SayHello:
def __call__(self,func):
def wrapper(*args,**kwargs):
print('你好,我要开始计算了')
return func(*args,**kwargs)
return wrapper
@SayHello()
def add(x,y):
res = x + y
print(f'{x}和{y}相加的结果是{res}')
return res
# 正常调用add函数
result = add(10,20)
print(result)
# 使用 SayHello去装饰 add函数(手动装饰)
# say = SayHello()
#
# add = say(add)
#
# result = add(10,20)
# print(result)
class SayHello:
def __init__(self,msg):
self.msg = msg
def __call__(self,func):
def wrapper(*args,**kwargs):
print(f'你好,我要开始{self.msg}计算了')
return func(*args,**kwargs)
return wrapper
@SayHello('加法')
def add(x,y):
res = x + y
print(f'{x}和{y}相加的结果是{res}')
return res
result = add(10,20)
print(result)
# 多个类装饰器的使用
class Test1:
def __call__(self,func):
def wrapper(*args,**kwargs):
print('我是test1追加的逻辑')
return func(*args, **kwargs)
return wrapper
class Test2:
def __call__(self,func):
def wrapper(*args,**kwargs):
print('我是test2追加的逻辑')
return func(*args, **kwargs)
return wrapper
@Test1()
@Test2()
def add(x, y):
res = x + y
print(f'{x}和{y}相加的结果是{res}')
return res
result = add(10,20)
print(result)60. 变量类型注解
变量类型注解: 给变量加上类型说明,可增强代码的可读性、让IDE的提示更友好
# 变量类型注解: 给变量加上类型说明,可增强代码的可读性、让IDE的提示更友好
num:int = 100
price: float = 12.5
message: str = '你好啊'
is_vip:bool = False
result: None = None # 语法上没有问题,但这么些没有意义
# 注意: 可以先写变量的类型注解,以后再赋值
school: str
print('*******')
school = '尚硅谷'
# hobby 是列表,并且列表中的所有元素必须是 str 类型
hobby:list[str] = ['抽烟','喝酒','烫头']
hobby.append('学习')
print(hobby)
# hobby 是列表,并且列表中的元素,可以是: str 或 int 类型
hobby:list[str | int] = ['抽烟','喝酒','烫头']
hobby.append('学习')
hobby.append(100)
# 上面这行代码的就写法如下:
from typing import Union
hobby:list[Union[str,int]] = ['抽烟','喝酒','烫头']
# cities 是集合,并且集合中所有元素必须是 str 类型
cities:set[str] = {'北京','上海','深圳'}
# citys 是集合,并且集合中所有元素可以是: str 或 float 或 bool 类型
citys:set[str | float | bool] = {'北京','上海','深圳'}
# persons 是字典,键是 str 类型,值是int类型
persons: dict[str,int] = {'张三':18,'李四':19,'王五': 20}
# persons 是字典,键是 str 或 int 类型,值是int类型
persons: dict[str | int,int] = {'张三':18,'李四':19,'王五': 20}
# 元组的类型声明有点特殊,各位要留意一下:
# scores 是元组,并且元组中仅包含一个int类型的元素
scores: tuple[int] = (60,)
# scores 是元组,并且元组中包含三个int类型的元素
scores: tuple[int,int,int] = (60,70,80)
# scores 是元组,并且元组中包含任意个数的元素,但每个元素的类型必须是int
scores: tuple[int,...] = (60,70,80)
# scores 是元组,并且元组中包含任意个数的元素,但每个元素的类型是int 或 str
scores: tuple[int | str,...] = (60,"70",80)
# Python 会根据初始赋值推导变量的类型:
# 1. 对于普通变量: 后续如果改变类型,不会警告。
# 2. 对于容器变量: 要求内部元素类型必须与推导出来的一致,否则就会警告。
x = 100
x = '尚硅谷'
y:list[int] = [10,20,30]
# y.append('40')
# y = 10061. 函数的类型注解
# 函数类型注解: 给函数的【参数】和【返回值】添加类型说明。
# 语法格式: 函数名(参数1:类型,参数2:类型) -> 返回值的类型。
# 示例1: 设置参数类型注解、设置返回值类型注解
def add(x:int,y:int) -> int:
return x + y
result = add(10,20)
print(result)
# 示例2: 参数有默认值(Python可以推导出参数的类型)、设置返回值类型
def add(x=1,y=1) -> int:
return x + y
result = add(10,20)
print(result)
# 示例3: 设置多个返回值的类型注解
def show_nums_info(nums:list[int]) -> tuple[int,int,float]:
max_value = max(nums)
min_value = min(nums)
result = max_value / min_value
return max_value,min_value,result
res = show_nums_info([10,20,30,40])
print(res)
# 示例4: 设置*args的类型注解,要求 args中的每个参数都必须是int类型
def add(*args:int) -> int:
return sum(args)
res = add(10,20,30,40)
print(res)
# 示例5: 设置**kwargs的类型注解,要求 kwargs中的每组参数的值,必须是str或int类型
def show_info(**kwargs: str | int):
print(kwargs)
show_info(name='张三',age=18,gender='男')
# 获取函数的注解信息
print(add.__annotations__)62. 错误与异常
错误: 代码本身有语法错误,解释器无法执行代码。---无法通过异常处理机制解决
age = 18
if age >= 18
print('成年人')异常: 代码在语法上没问题,但执行过程中出现了问题。---可以通过异常处理机制解决
一些开发中常见的异常:
- ZeroDivisionError: 当除数为0时触发。
# 1. ZeroDivisionError: 当除数为0时触发。
num1 = 100
num2 = 0
result = num1 / num22.Typeerror: 当操作的数据类型不正确或不兼容时触发。
result = '10' + 53.AttributeError: 当对象没有指定的属性或方法时触发。
# 演示1
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
p1 = Person('张三',18)
print(p1.name)
print(p1.age)
print(p1.gender)
# 演示2
nums = [10,20,30]
nums.add(40)- IndexError: 当索引超出范围(索引越界)时触发
nums = [10,20,30,40]
print(nums[5])- NameError: 当使用了不存在的变量时触发
print(school)- KeyError: 当访问字典中不存在的key时触发
person = {name: '张三',age:18}
print(person.gender)- ValueError: 当值不合法,但类型正确时触发。
int('hello')63. 异常处理
为什么要进行异常处理?
- 程序运行过程中出现的异常,如果得不到处理,那程序就会立刻崩溃,导致后续代码无法执行。
- 异常处理不是让异常消失,而是将异常捕获到,随后根据异常的具体情况,来执行指定的逻辑。
# 为什么要进行异常处理?
# 程序运行过程中出现的异常,如果得不到处理,那程序就会立刻崩溃,导致后续代码无法执行。
# 异常处理不是让异常消失,而是将异常捕获到,随后根据异常的具体情况,来执行指定的逻辑。
print('欢迎使用本程序')
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
result = a / b
print(f'{a}除以{b}的结果是: {result}')
print('******我是后续的其他逻辑1******')
print('******我是后续的其他逻辑2******')
# 2.异常处理(初级):
# 1. 将可能出现异常的代码放在 try中,出现异常后的处理代码写在 except中
# 2. 如果try中的代码出现异常,那try中的后续代码将不会执行,并自动跳转到except中处理异常
# 3. 如果 try 中的代码没有异常,那 except 中的代码就不会执行
# 4. 无论是否发生异常,try-except 后面的代码都会继续执行
# 5. 直接写except 会捕获到 Python 中所有的异常 --- 实际开发中不推荐这样做。
print('欢迎使用本程序')
try:
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
result = a / b
print(f'{a}除以{b}的结果是: {result}')
except:
print('抱歉,程序出现了异常!')
print('******我是后续的其他逻辑1******')
print('******我是后续的其他逻辑2******')
# 3.异常处理(捕获指定的类型的异常):
print('欢迎使用本程序')
try:
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
result = a / b
print(f'{a}除以{b}的结果是: {result}')
except ZeroDivisionError:
print('程序异常: 0不能作为除数!')
except ValueError:
print('程序异常: 您输入的必须是数字')
print('******我是后续的其他逻辑1******')
print('******我是后续的其他逻辑2******')
# 4.验证一下异常类之间的继承关系
print(issubclass(ZeroDivisionError,ArithmeticError))
print(issubclass(ZeroDivisionError,Exception))
print(issubclass(ValueError,Exception))
print(issubclass(KeyboardInterrupt,Exception))
# 5.多个 except 从上往下匹配,匹配成功后不再向下匹配。
print('欢迎使用本程序')
try:
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
print(x)
result = a / b
print(f'{a}除以{b}的结果是: {result}')
except ZeroDivisionError:
print('程序异常: 0不能作为除数!')
except ValueError as e:
print('程序异常: 您输入的必须是数字')
except Exception as e:
print(f'!程序异常,异常信息:{e}')
print(f'!程序异常,异常类型:{type(e)}')
print(f'!程序异常,异常参数:{e.args}')
print(f'!程序异常,异常的文件:{e.__traceback__.tb_frame.f_code.co_filename}')
print(f'!程序异常,异常的具体行数:{e.__traceback__.tb_lineno}')
# 通过 traceback 来回溯异常
import traceback
print(traceback.format_exc())
print('******我是后续的其他逻辑1******')
print('******我是后续的其他逻辑2******')
# 6. 一个except,也可以捕获不同的异常
print('欢迎使用本程序')
try:
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
print(x)
result = a / b
print(f'{a}除以{b}的结果是: {result}')
except (ZeroDivisionError,ValueError,Exception) as e :
if isinstance(e,ZeroDivisionError):
print('程序异常: 0不能作为除数!')
elif isinstance(e,ValueError):
print('程序异常: 您输入的必须是数字')
else:
print(f'程序异常:{e}')
# except ZeroDivisionError:
# print('程序异常: 0不能作为除数!')
# except ValueError as e:
# print('程序异常: 您输入的必须是数字')
# except Exception as e:
# print(f'程序异常:{e}')
print('******我是后续的其他逻辑1******')
print('******我是后续的其他逻辑2******')
# 7. 异常处理的完整写法:
# 1. try: 尝试去做可能会出现异常的事情
# 1. except: 出现异常时的处理(出现异常时怎么补救)
# 3.else: 如果一切顺利(没有异常出现)要做的事
# 4.finally: finally: 无论有没有异常,都要做的事
print('欢迎使用本程序')
try:
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
# print(x)
result = a / b
print(f'{a}除以{b}的结果是: {result}')
except (ZeroDivisionError,ValueError,Exception) as e :
if isinstance(e,ZeroDivisionError):
print('程序异常: 0不能作为除数!')
elif isinstance(e,ValueError):
print('程序异常: 您输入的必须是数字')
else:
print(f'程序异常:{e}')
else:
print('挺好的,try中的代码没有任何异常!')
finally:
print('无论有没有异常,我的计算都结束了!')
# except ZeroDivisionError:
# print('程序异常: 0不能作为除数!')
# except ValueError as e:
# print('程序异常: 您输入的必须是数字')
# except Exception as e:
# print(f'程序异常:{e}')
print('******我是后续的其他逻辑1******')
print('******我是后续的其他逻辑2******')64. 手动抛出异常
当程序遇到不符合预期情况时,可以使用 raise 语句手动触发(抛出)异常。
print('欢迎使用年龄判断系统')
try:
age = int(input('请输入你的年龄: '))
if 18 <= age <= 120:
print('成年')
elif 0 <= age < 18:
print('未成年')
else:
# print('输入的年龄有误!(年龄应该为0~120的整数)')
raise ValueError('年龄应该为0~120的整数')
except Exception as e:
print(f'程序异常: {e}')65. 异常的传递机制
- 如果异常没有被当前代码块所捕获处理,那该异常就会沿着调用链,逐层传递给其调用者。
- 如果所有调用者,都没有捕获该异常,那最终程序将因【未处理异常】而意外终止
# 异常的传递机制:
# 1. 如果异常没有被当前代码块所捕获处理,那该异常就会沿着调用链,逐层传递给其调用者。
# 2. 如果所有调用者,都没有捕获该异常,那最终程序将因【未处理异常】而意外终止
def test1():
print('******test1开始******')
try:
result = '100' + 100
except Exception as e:
print(f'程序异常: {e}')
print('******test1结束******')
def test2():
print('******test2开始******')
test1()
print('******test2结束******')
def test3():
print('******test3开始******')
test2()
print('******test3结束******')
test3()66. 自定义异常
- 由开发人员自己定义一个异常类,用来表示代码中"更具体、更有业务含义"的异常。
- 具体规则: 定义一个类(类名通常以Error结尾),继承 Exception 类或它的子类。
# 自定义异常类:
# 1. 由开发人员自己定义一个异常类,用来表示代码中"更具体、更有业务含义"的异常。
# 2. 具体规则: 定义一个类(类名通常以Error结尾),继承 Exception 类或它的子类。
class SchoolNameError(Exception):
def __init__(self,msg):
super().__init__('【校名异常】' + msg)
def check_school_name(name):
if len(name) > 10:
raise SchoolNameError('学校名过长')
else:
print('学校名是合法的')
try:
check_school_name('atguiguuuuuuuuuuuuuu')
except SchoolNameError as e:
print(f'程序异常: {e}')67. 模块
模块概述:
- 在Python中,一个.py文件就是一个模块(Module)
- 模块中可以包含: 变量、函数、类、等很多内容
- 通常把能够实现某一特定功能的代码,集中放在一个模块中(模块就类似于一个工具箱)。
- 模块可以提高代码的可维护性 与 可复用性,还可以避免命名冲突。
模块的分类:
Python中的模块分为三类,分别是: 标准库模块、自定义模块、第三方模块。
模块命名注意点:
- 要符合标识符命名规则
- 模块名(.py文件名)区分大小写
- 不要与标准库模块同名(一旦同名,Python会优先引入标准库模块)
常见的模块导入方式
- import 模块名
- import 模块名 as 别名
- from 模块名 import 具体内容1,具体内容2,.。。。
- from 模块名 import 具体内容1 as 别名1,具体内容2 as 别名2,。。。。。。
- from 模块命 import *(不推荐,容易造成命名污染)
关于__all__:
- 在Python模块中,可通过__all__来控制【from 模块 import *】能导入哪些内容
- __all__的值可以是: 列表、元组。
关于__name__:
- __name__是每个Python模块(.py文件) 都拥有的一个内置变量。
- 它的具体值取决于模块的运行方式:
- 作为主程序直接运行,name__的值是__main
- 作为模块被导入到其他程序中运行,__name__的值是模块的文件名(不带.py)
68.标准库模块
- Python中的模块分为三类,分别是: 标准库模块、自定义模块、第三方模块
- 标准库模块:随着 Python 一起安装在我们电脑上的哪些模块
- 有一些标准库模块是用c语言实现的,这些用c语言实现的模块,又称: 【内置模块】。
69.包
包概述:
- 在Python中,【包含__init__.py的文件夹】就是一个包(Package)
- 我们通常会把【某个特定功能相关的所有模块】放入一个包中。
- 使用包可以进一步提升代码的: 可维护性、可复用性,便于管理大型项目。
包与模块的关系:
- 一个模块就是一个.py文件,包是用来"管理模块"的目录(文件夹)
- 一个包中可以有多个模块,也可以有多个子包。
包的分类:
Python 中的包分为三类,分别是: 标准库包、自定义包、第三方包。
包命名注意点:
- 要符合标识符命名规范
- 包名区分大小写(建议全部使用小写字母)
- 不要与标准库包同名
包的多种导入方式
- import 包名.模块名
import trade.order
import trade.pay
trade.order.create_order()
trade.pay.wechat_pay()- import 包名.模块名 as 别名
import trade.order as dd
import trade.pay as zf
dd.create_order()
zf.wechat_pay()- from 包名.模块名 import 具体内容1,具体内容2,。。。。。
from trade.order import max_order_amount,create_order
from trade.pay import timeout,wechat_pay
print(max_order_amount)
print(timeout)
create_order()
wechat_pay()- from 包名.模块名 import 具体内容1 as 别名1,具体内容2 as 别名2,。。。。。
from trade.order import max_order_amount,create_order
from trade.pay import timeout,wechat_pay as w_pay
print(max_order_amount)
print(timeout)
create_order()
w_pay()- from 包名.模块名 import *
from trade.order import *
from trade.pay import *
print(max_order_amount)
create_order()
cancel_order()
show_info()
print(timeout)
wechat_pay()
ali_pay()
show_info()- from 包名 import 模块名
from trade import order,pay
order.create_order()
order.cancel_order()
pay.wechat_pay()
pay.ali_pay()- from 包名 import 模块名 as 别名
from trade import order as dd,pay as p
dd.create_order()
dd.cancel_order()
p.wechat_pay()
p.ali_pay()
# 关于 __init__.py文件:
# 1. __init__.py是包的初始化文件,在包被导入时,__init__.py会被自动调用
# 2. __init__.py是可以编写一些包的初始化逻辑
# 3. __init__.py中所定义的内容,会被【from 包名 import *】形式全部引入
# 4. __init__.py中也可以使用__all__ 来控制包中的哪些模块可以被【from 包名 import *】 引入- from 包名 import *
from trade import *
print(a)
print(b)
print(order.max_order_amount)- import 包名
import trade
print(trade.a)
print(trade.b)70.常用的pip命令

71.迭代器
知识点1: 能被 for 循环遍历的对象,被称为: 可迭代对象(iterable)
names = ['张三','李四','王五']
citys = ('北京','上海','深圳')
msg = 'hello'
age = 10
def test():
pass
for item in citys:
print(item)知识点2: 可迭代对象(iterable)能调用到 __iter__方法。
names = ['张三','李四','王五']
citys = ('北京','上海','深圳')
msg = 'hello'
age = 10
def test():
pass
names.__iter__()
citys.__iter__()
msg.__iter__()
print(hasattr(names,'__iter__'))
print(hasattr(citys,'__iter__'))
print(hasattr(msg,'__iter__'))
print(hasattr(age,'__iter__'))
print(hasattr(test,'__iter__'))知识点3: 调用__iter__方法会得到: 迭代器(iterator)
备注1: __iter__是一个魔法方法,当调用iter函数时,__iter__会自动调用。
备注2: 可迭代对象.iter() 等价于 iter(可迭代对象)。
备注3: 如果 iter(obj)能得到一个迭代器(iterator),那obj就是可迭代对象。
names = ['张三','李四','王五']
citys = ('北京','上海','深圳')
msg = 'hello'
print(names.__iter__())
print(citys.__iter__())
print(msg.__iter__())
print(iter(names))
print(iter(citys))
print(iter(msg))知识点4: 迭代器(iterator)拥有__next__方法,每次调用都会根据当前的状态,返回下一个元素
备注1: 迭代器.next() 等价于 next(迭代器)
备注2: 当所有元素全部取出后,若继续调用 next 方法,Python会抛出 StopIteration 异常。
names = ['张三','李四','王五']
it = iter(names)
print(it.__next__())
print(it.__next__())
print(it.__next__())
print(next(it))
print(next(it))
print(next(it))
#for 循环背后的工作逻辑
names = ['张三','李四','王五']
for item in names:
print(item)
#调用可迭代对象的__iter__方法 获取到一个迭代器
it = iter(names)
#开启一个无限循环
while True:
try:
# 调用__next__方法,获取下一个元素
item = next(it)
print(item)
except StopIteration:
# 捕获 StopIteration异常,随后结束循环
break知识点5: 迭代器(iterator)也拥有 __iter__方法,并且其返回值是迭代器自身。
这么设计的原因如下: 让for循环也能遍历迭代器(即: 为了让iter(迭代器)不出错)
names = ['张三','李四','王五']
it = iter(names)
print(it)
print(iter(it))
print(it == iter(it))
print(iter(iter(it)))
for item in it:
print(item)知识点6: 迭代器协议
- 能被iter()接受
- 能被next()一步一步取值
手写迭代器
# 迭代器是一次性的,状态只会向前推进,且不会自动重置(迭代器在遍历的过程中会被消耗)
# region
# names = ['张三','李四','王五']
# it1 = iter(names)
# it2 = iter(names)
#
# print(next(it1))
# print(next(it1))
# print(next(it1))
# print(next(it2))
# print(next(it2))
# print(next(it2))
# for item in it1:
# print(item)
#
# for item in it2:
# print(item)
# endregion
# 需求: 让for循环可以遍历Person的实例对象
# 实现方式一:
# region
# class Person:
# def __init__(self,name,age,gender,address):
# self.name = name
# self.age = age
# self.gender = gender
# self.address = address
#
# def __iter__(self):
# print(self)
# return PersonIterator(self)
#
# class PersonIterator:
# def __init__(self,p):
# # 将外部传进来的数据保存好
# self.p = p
# # 设置迭代器的初始化状态(指针的位置)
# self.index = 0
# # 配置好要遍历的内容
# self.attrs = [p.name,p.age,p.gender,p.address]
# def __iter__(self):
# return self
# # 每次调用__next__方法,会根据当前的状态,返回下一个元素
# def __next__(self):
# # 如果指针的位置超出范围,那就抛出StopIteration异常
# if self.index >= len(self.attrs):
# raise StopIteration
# # 获取要返回的内容
# value = self.attrs[self.index]
# # 更新迭代器的状态
# self.index += 1
# return value
# #
# # # 目标:
# p1 = Person('张三',18,'男','北京昌平')
# it = iter(p1)
# for item in it:
# print(item)
#
# for item in it:
# print(item)
# endregion
# 实现方式二:
# region
# class Person:
# def __init__(self,name,age,gender,address):
# self.name = name
# self.age = age
# self.gender = gender
# self.address = address
# # 设置迭代器的初始化状态(指针位置)
# self.__index = 0
# # 配置好要遍历的内容
# self.__attrs = [name,age,gender,address]
#
#
# def __iter__(self):
# # self.__index = 0
# return self
#
# def __next__(self):
# if self.__index >= len(self.__attrs):
# raise StopIteration
# value = self.__attrs[self.__index]
# self.__index += 1
# return value
#
# # 目标
# # 下面的p1即是可迭代对象,又是迭代器
# p1 = Person('张三',18,'男','北京昌平')
# for item in p1:
# print(item)
# endregion
# 进阶: 迭代器玩的就是__next__
from cn2an import an2cn
class Person:
def __init__(self,name,age,gender,address):
self.name = name
self.age = age
self.gender = gender
self.address = address
# 设置迭代器的初始化状态(指针位置)
self.__index = 0
# 配置好要遍历的内容
self.__attrs = [name,age,gender,address]
def __iter__(self):
# self.__index = 0
return self
def __next__(self):
if self.__index >= len(self.__attrs):
raise StopIteration
value = self.__attrs[self.__index]
# 将字符串转为大写
if isinstance(value,str):
value = value.upper()
# 将数字转为汉语
if isinstance(value,int):
value = an2cn(value)
self.__index += 1
return value
#
# # 目标
# # 下面的p1即是可迭代对象,又是迭代器
p1 = Person('zhangsan',18,'男','北京昌平')
for item in p1:
print(item)迭代器的优势
import tracemalloc
import sys
# 使用迭代器实现(你的版本)
class Fibo:
def __init__(self, total):
self.total = total
self.index = 0
self.pre = 1
self.cur = 1
def __iter__(self):
return self
def __next__(self):
if self.index >= self.total:
raise StopIteration
if self.index < 2:
value = 1
else:
value = self.pre + self.cur
self.pre = self.cur
self.cur = value
self.index += 1
return value
# 不用迭代器实现
def fibo_list(total):
if total <= 0:
return []
if total == 1:
return [1]
nums = [1, 1]
for i in range(2, total):
nums.append(nums[-1] + nums[-2])
return nums
# 测试迭代器版本的内存
print("=== 测试迭代器版本 ===")
tracemalloc.start()
f_iter = Fibo(10000) # 只创建对象,内存占用很小
# 真正遍历生成所有数据
for item in f_iter:
pass
m1 = tracemalloc.get_traced_memory()
print(f'迭代器峰值内存: {m1[1] / 1024 / 1024} MB')
tracemalloc.stop()
# 测试列表版本的内存
print("\n=== 测试列表版本 ===")
tracemalloc.start()
f_list = fibo_list(10000) # 一次性生成所有数据并存入列表
m2 = tracemalloc.get_traced_memory()
print(f'列表峰值内存: {m2[1] / 1024 / 1024:.2f} MB')
tracemalloc.stop()72.生成器
生成器:
- 生成器函数: 函数体中如果出现了 yield 关键字, 那该函数是【生成器函数】。
- 生成器对象: 调用【生成器函数】时,其函数体不会立刻执行,而是返回一个【生成器对象】。
备注: 不管能否执行到 yield 所在的位置,只要函数中有yield关键字,那该函数,就是【生成器函数】。
def demo():
print('demo函数开始执行了')
print(100)
yield
a = 200
print(a)
a = demo()
print(a)下载【生成器函数】中的代码,需要通过【生成器对象】来执行:
- 调用【生成器对象】的 next 方法,会让【生成器函数】中的代码开始执行。
- 当【生成器函数】中的代码开始执行后,遇到yield 会"暂停"执行,并且其内部会记录"暂停"的位置。
- 后续调用 next 方法,都会从上一次暂停的位置,继续运行,直到再次遇到yield
- 遇到 return 会抛出 StopIteration 异常,并将 return 后面的表达式,作为异常信息
- yield 后面所写的表达式,会作为本次 next 方法的返回值。
def demo():
print('demo函数开始执行了')
print(100)
yield '我是第一个yield所返回的数据'
a = 200
print(a)
yield '我是第二个yield所返回的数据'
b = 300
print(b)
return '尚硅谷'
d = demo()
result = next(d)
print(result)
result2 = next(d)
print(result2)
try:
next(d)
except StopIteration as e:
print(e)
print(d)
next(d)
next(d)
next(d)生成器对象是一种特殊的迭代器(本质是通过 yield 自动实现了迭代器协议)
def demo():
print('demo函数开始执行了')
print(100)
yield '我是第一个yield所返回的数据'
a = 200
print(a)
yield '我是第二个yield所返回的数据'
b = 300
print(b)
return '尚硅谷'
d = demo()
result = next(d)
print(result)
result2 = next(d)
print(result2)
try:
next(d)
except StopIteration as e:
print(e)
print(d)
next(d)
next(d)
next(d)
endregion
3.生成器对象是一种特殊的迭代器(本质是通过 yield 自动实现了迭代器协议)
region
def demo():
print('demo函数开始执行了')
print(100)
yield '我是第一个yield所返回的数据'
a = 200
print(a)
yield '我是第二个yield所返回的数据'
b = 300
print(b)
return '尚硅谷'
d = demo()
#验证生成器对象d,和迭代器一样,也拥有: __iter__ 和 __next__ 方法
print(hasattr(d,"__iter__"))
print(hasattr(d,"__next__"))
#验证生成器对象的__iter__方法,和迭代器一样,返回的也是自身
result = iter(d)
print(result == d)
#for循环遍历
for item in d:
print(item)
#for循环背后的逻辑
gen = iter(d)
while True:
try:
value = next(gen)
print(value)
except StopIteration:
breakyield 也能写在循环里
def create_car(total):
for index in range(total):
yield f'我是第{index}台车'
cars = create_car(5)
# 调用一次cars的__next__方法,就会得到一台车
c1 = next(cars)
print(c1)
c2 = next(cars)
print(c2)
c3 = next(cars)
print(c3)
c4 = next(cars)
print(c4)
c5 = next(cars)
print(c5)
for car in cars:
print(car)yield from 能把一个【可迭代对象】里的东西依次 yield 出去。(替代: for + yield)
def demo():
nums = [10,20,30,40]
# for n in nums:
# yield n
yield from nums
d = demo()
r1 = next(d)
print(r1)
r2 = next(d)
print(r2)
r3 = next(d)
print(r3)
r4 = next(d)
print(r4)
for item in d:
print(item)使用: 生成器.send(值)可以让生成器继续执行的同时,给上一次 yield 传值
备注1: next只能取值,send 既能取值,也能送值
备注2: 第一次启动生成器,不能传值!
def demo():
print('demo函数开始执行了')
print(100)
a = yield '我是第一个yield所返回的数据'
print(a)
b = yield '我是第二个yield所返回的数据'
print(b)
return '尚硅谷'
d = demo()
r1 = d.send(None)
print(r1)
r2 = d.send(666)
print(r2)
try:
d.send(888)
except StopIteration as e:
print(e)用生成器遍历Person类的实例对象
class Person:
def __init__(self,name,age,gender,address):
self.name = name
self.age = age
self.gender = gender
self.address = address
self.__atter = [name,age,gender,address]
def __iter__(self):
# yield self.name
# yield self.age
# yield self.gender
# yield self.address
yield from self.__atter
p1 = Person('张三',18,'男','北京昌平')
# 目标:
for attr in p1:
print(attr)用生成器实现斐波那契数列
def fibo(total):
pre = 1
cur = 1
for index in range(total):
if index < 2:
yield 1
else:
value = pre + cur
pre = cur
cur = value
yield value
f1 = fibo(10)
for item in f1:
print(item)
# 无论是迭代器,还是生成器对象,都可以用list、tuple、set等直接拿到其里面的所有内容(注意: 容易挤爆内存)生成器表达式: 一种类似列表推导式的语法,快速创建生成器对象的方法。
语法格式: (表达式 for 变量 in 可迭代对象)
什么时候适合用生成器表达式? --- 当“每个结果”,只依赖当前这一个元素时。
nums = [10,20,30,40]
# 列表推导式
result = [n * 2 for n in nums]
print(result)
# 生成器表达式
result2 = (n * 2 for n in nums)
print(result2)
# for item in result2:
# print(item)73.文件相关操作
1. 前序知识
文件的分类: 1.纯文本文件、2.二进制文件
纯文本文件:
- 读取和存储时,要遵循某种【字符编码】规范(如: UTF-8 等)进行编码和解码,最终以【二进制】的形式存储。
- 【纯文本文件】最终会呈现为: 可以直接阅读的文本信息。
- 常见的【纯文本文件】有:.txt .py .md .html等。
二进制文件
- 读取和存储时,不涉及字符编码,会按照某种【文件格式规范】把内容转为【二进制】数据进行存储。
- 二进制文件需要由【能够识别其格式的软件】进行解析,最终的呈现形式多种多样(音频、视频、图像、幻灯片等)。
- 常见的二进制文件有:.mp3 .mp4 .doc .ppt .jpg .png等
绝对路径 vs 相对路径:
- 绝对路径: 从文件系统的【根目录】开始,完整描述文件或目录所在的位置。
- 相对路径: 以当前【工作目录】为参照,描述目标文件或目录相对于它的位置。
2. 读取文件
Python操作文件的标准流程:
- 创建【文件对象】
- 操作文件(读取、写入 等)
- 关闭文件
文件操作的核心 --- open函数: 它可以打开或创建文件,且支持多种操作模式,返回值时【文件对象】。
open 函数最常用的三个参数如下:
- file: 要操作的文件路径
- mode: 文件的打开模式
r: 读取(默认值)
w: 写入,并先截断文件
x: 排他性创建,如果文件已存在,则创建失败
a: 打开文件用于写入,如果文件存在,则在文件末尾追加内容
b: 二进制模式
t: 文本模式(默认值)
+: 打开用于更新(读取与写入) - encoding: 字符编码
读取操作1: 使用【文件对象】的read 方法,读取文件中的内容。
#read 方法说明:
- read(size) 中的size是可选参数。
若不传递 size 参数,表示: 读取文件中所有的内容(注意内存占用)
若传递了 size 参数,表示: 读取文件中指定个数的字符,或指定大小的字节。- read 会从上一次 read 的位置继续读取(指针思想), 若到达文件末尾后继续读取,将返回空字符串。
#read 方法说明:
# 1.read(size) 中的size是可选参数。
# 若不传递 size 参数,表示: 读取文件中所有的内容(注意内存占用)
# 若传递了 size 参数,表示: 读取文件中指定个数的字符,或指定大小的字节。
# 2.read 会从上一次 read 的位置继续读取(指针思想), 若到达文件末尾后继续读取,将返回空字符串。
# 第一步.创建【文件对象】
file = open(file='a.txt',mode='rt',encoding='utf-8')
file = open('a.txt','rt',encoding='utf-8')
file = open('a.txt','rt',encoding='utf-8')
# 第二步.操作文件(读取)
# 多次调用read去逐步读取文件
result = file.read(2)
result2 = file.read(2)
result3 = file.read(2)
print(repr(result))
print(repr(result2))
print(result)
print(result2)
print(result3)
# 用循环配合多次read(对内存友好)
while True:
result = file.read(2)
if(result == ''):
break
print(result,end='')
# 第三步.关闭文件
file.close()读取操作2: 使用【文件对象】的read 方法,读取文件中的内容。
readline 方法说明:
- readline(size) 中的size是可选参数。
若不传递 size 参数,表示: 读取文当前这一行所有的内容
若传递了 size 参数,表示: 读取当前行时,最多能读取的字符数,或字节数(size不是行数)。 - readline 会从上一次 readline 的位置继续读取(指针思想), 若到达文件末尾后继续读取,将返回空字符串。
# 第一步.创建【文件对象】
file = open('a.txt','rt',encoding='utf-8')
# 第二步.操作文件(读取)
r1 = file.readline()
r2 = file.readline()
r3 = file.readline()
r4 = file.readline()
print(r1.strip())
print(r2.strip())
print(r3.strip())
print(r4.strip())
# 第三步.关闭文件
file.close()读取操作3: 使用 for 循环直接遍历文件对象
# 第一步.创建【文件对象】
file = open(file='a.txt',mode='rt',encoding='utf-8')
# 第二步.操作文件(读取)
for line in file:
print(line,end='')
# 第三步.关闭文件
file.close()读取操作4: 使用文件对象的 readlines 方法,一次性按行读完,返回一个列表
readlines 方法说明:
- readlines(hint) 中的hint是可选参数。
若不传递 hint 参数,表示: 读取当前文件的所有行
若传递了 hint 参数,表示: 期望读取的【字符个数 或 字节数的上限】(hint不是行数) - 注意: readlines 是一次性读取文件的所有内容,所以不适合读取体积较大的文件。
# 第一步.创建【文件对象】
file = open(file='a.txt',mode='rt',encoding='utf-8')
# 第二步.操作文件(读取)
result = file.readlines()
print(result)
# # 第三步.关闭文件
file.close()最佳实践: 使用with 上下文管理器,结合for循环遍历,逐行读取文件。
with open('a.txt','rt',encoding='utf-8') as file:
for line in file:
print(line,end='')3. 关于with
Python 中的 with 主要用于管理程序中"需要成对出现的操作",例如:
上锁 / 解锁
打开 / 关闭
借用 / 归还最终目标: 编码者只管做具体的事,"进入"和"离开"的事,让Python自动处理
语法格式如下:
with 能得到一个上下文管理器的表达式 as 变量:
具体的事1
具体的事2
具体的事3上下文管理器协议:
(1). __enter__方法: with 中的代码执行【之前】调用,其返回值会赋值给 as 后的变量
(2). __exit__方法: with 中的代码执行【结束后】调用(无论是with中否出现异常都会调用)
# 定义一个 Person 类,让其实例对象遵循: 上下文管理器协议
class Person:
def __init__(self,name,age):
self.name = name
self.age = age
def speak(self):
print(f'我叫{self.name},年龄是{self.age}')
def __enter__(self):
print('-------我是进入的逻辑-------')
return self
# 当 with 中的代码发生异常时,__exit__方法的返回值规则如下:
# 返回真: 表示异常【已经】被处理,异常【不会】被继续抛出。
# 返回假: 表示异常【没有】被处理,异常【会】被继续抛出。
def __exit__(self, exc_type, exc_val, exc_tb):
print('-------我是离开的逻辑-------')
# exc_type 异常类型
# exc_val 异常对象
# exc_tb 异常追踪信息
if exc_type:
print(f'异常类型:{exc_type}')
print(f'异常对象:{exc_val}')
print(f'异常追踪信息:{exc_tb}')
return True
# p1 = Person('张三',18)
# p1.speak()
# 1.计算with后面的表达式,得到一个【上下文管理器】
# 2.调用【上下文管理器】的 __enter__方法,并将其返回值赋给 as 后面的变量
# 3. 执行with 所管理的代码
# 4.无论with中的代码,是正常结束,还是发生异常,都会自动调用【上下文管理器】的__exit__方法
with Person('张三',18) as p1:
p1.speak()
# p1.study()
print(666)4. 文件写入
在 Python 中文件写入时,并不是每写一次就立刻落盘,而是: 先写到“缓冲区”里。
seek(offset,whence)方法: 用于改变文件对象指针的位置,参数说明如下:
offset: 偏移量,要移动多少距离
whence: 参考点,从哪里开始计算偏移,有三种取值:
0: 从文件开头计算(默认值)
1: 从当前位置计算
2: 从文件末尾计算
注意: 在文本模式下,不要随意去定义中文字符位置,否则可能破坏文件编码。
# open 函数最常用的三个参数如下:
# 1.file: 要操作的文件路径
# 2.mode: 文件的打开模式
# r: 读取(默认值)
# w: 写入,并先截断文件
# x: 排他性创建,如果文件已存在,则创建失败
# a: 打开文件用于写入,如果文件存在,则在文件末尾追加内容
# b: 二进制模式
# t: 文本模式(默认值)
# +: 打开用于更新(读取与写入)
# 测试 w 模式
with open('b.txt','wt',encoding='utf-8') as file:
file.write('你好')
# 测试 x 模式
with open('demo.txt', 'xt', encoding='utf-8') as file:
file.write('你好')
# 测试 a 模式
with open('demo.txt', 'at', encoding='utf-8') as file:
file.write('你好')
# 在 Python 中文件写入时,并不是每写一次就立刻落盘,而是: 先写到“缓冲区”里。
with open('demo.txt','rt+',encoding='utf-8') as file:
file.seek(0,2)
file.write('你好1')
# 测试rt+
with open('demo.txt','rt+',encoding='utf-8') as file:
# seek(offset,whence)方法: 用于改变文件对象指针的位置,参数说明如下:
# offset: 偏移量,要移动多少距离
# whence: 参考点,从哪里开始计算偏移,有三种取值:
# 0: 从文件开头计算(默认值)
# 1: 从当前位置计算
# 2: 从文件末尾计算
# 注意: 在文本模式下,不要随意去定义中文字符位置,否则可能破坏文件编码。
file.seek(0,2)
file.write('你好1')
# 测试wt+
with open('demo.txt','wt+',encoding='utf-8') as file:
file.write('Python,你好啊')
file.seek(0)
result = file.read()
print(result)
# 测试xt+
with open('demo.txt','xt+',encoding='utf-8') as file:
file.write('Python,你好啊')
file.seek(0)
result = file.read()
print(result)
# 测试at+
with open('demo.txt','at+',encoding='utf-8') as file:
file.write('Python,你好啊')
file.seek(0)
result = file.read()
print(result)5. 目录操作
- os.mkdir(path): 创建"单级"目录(如果目录已经存在,则会排除异常)
import os
import shutil
os.mkdir('demo/a')- os.makedirs(path): 创建多级目录(如果路径中的所有目录都已经存在,则会抛出异常)
os.makedirs("demo/aa/bb")- os.rmdir(path): 删除空目录(如果目录不存在,或目录非空,都会抛出异常)
os.rmdir('demo')- os.removedirs(path): 递归删除空目录,在成功删除末尾一级目录后,会"向上"尝试把父级目录也删除(直到父目录不是空目录)
os.removedirs("demo")- os.path.exists(path): 判断路径是否存在(文件/目录都算)
result = os.path.exists('demo/aa/bb')
print(result)- os.path.isdir(path): 用于判断路径,具体规则如下:
1.路径不存在 ========> 返回False
2.路径存在,但指向的是文件 ========> 返回False
3.路径存在,并且是目录 ========> 返回True
result = os.path.isdir('demo/aa/bb')
print(result)- os.path.isfile(path): 判断是否为文件:
result = os.path.isfile('demo/aa/bb')
print(result)- os.scandir(path): 扫描指定目录:
result = os.scandir('demo/aa')
for item in result:
print(item)
print(item.name)
print('目录' if item.is_dir() else '文件',item.name)- os.walk(path): 按层级,递归地遍历指定目录下,所有的子目录和文件
result = os.walk('demo/aa')
for item in result:
print(item)【危险操作】: 删除有内容的目录
shutil.rmtree('demo')6. 小练习
练习1: 将一个二进制文件复制到指定位置
# 源文件
import os.path
import time
# source = 'demo.txt'
# # 目标目录
# target = 'D:/media'
#
# # 如果目标目录不存在,那就去创建
# if not os.path.isdir(target):
# os.makedirs(target)
#
# with open(source,'rt',encoding='utf-8') as f1,open(target + '/' + 'demo.txt','wt',encoding='utf-8') as f2:
# while True:
# # 每次只读取1KB
# data = f1.read(1024)
# # 如果文件读取完毕了,就跳出循环
# if not data:
# break
# # 向目标文件中写入数据
# f2.write(data)练习2: 日志记录
- 用户输入用户名和密码后,程序进行校验:
- 用户名不存在,提示"用户名未注册",并记录日志
- 用户名存在,但密码错误,提示“密码错误”,并记录日志
- 用户名和密码均正确,提示"登录成功",并记录日志。
users = {
'张三': '123456',
'李四': '888888',
'王五': 'abc123',
}
# 提示输入信息
username = input('请输入用户名:')
password = input('请输入密码:')
# 获取当前的时间
now = time.strftime('%Y-%m-%d %H:%M:%S')
if username not in users:
print('用户名未注册')
with open('log.txt','at',encoding='utf-8') as file:
file.write(f'{now} {username} 登录失败(用户未注册)\n')
elif users[username] != password:
print('密码不正确!')
with open('log.txt','at',encoding='utf-8') as file:
file.write(f'{now} {username} 密码错误\n')
else:
print('登录成功')
with open('log.txt','at',encoding='utf-8') as file:
file.write(f'{now} {username} 登录成功\n')74.并发_并行_同步_异步_进程_线程
1. 一些概念
一、并发 vs 并行:
1.并发:
概念: 在一段时间内,当CPU面对多个任务时,会将每个任务交替着执行一段时间。
特点:
(1).对于某个瞬间,CPU实际上只在执行一个任务
(2).CPU通过高频切换不同的任务,让每个任务都能得到推进,仿佛多个任务在"同时执行"
2.并行:
概念: 并行依赖于多个CPU,或多核心的CPU,在同一时刻,每个核心都在执行不同的任务
特点:
(1).对于某个瞬间,每个CPU(或每个核心)都在执行不同的任务
(2).通过多个CPU(或多个核心)同时工作的方式,让多个任务真的在同时执行。
说明: 在现在操作系统中,并发与并行通常都是同时存在的。
import os
print(os.cpu_count())二、同步 vs 异步
1.同步(sync):
概念: 发起一个任务之后,需要等该任务完成后,才能继续执行后续任务。
表现: 当前执行流会被【阻塞】
2.异步(async):
概念: 发起一个任务之后,不必等该任务完成,就可以继续执行其他任务。
备注: 虽然不必等待任务完成,但任务完成后,仍然可以通过特定方式获取结果。
表现: 当前执行流不会被【阻塞】
三、注意区分概念:
并发 / 并行: 描述的是任务如何被执行,即: 多个任务在执行时,CPU要如何处理
同步 / 异步: 描述的是任务如何被组织和等待,即: 要不要等当前发起的任务执行完,再进行下一个任务。
注意点: CPU 的核心数和执行速度,不会改变任务之间的逻辑依赖关系!例如:
一旦任务1、任务2、任务3之间被设计为同步关系,那么: 即便 CPU 切换任务的速度再快,核心数量再多,也不会在【任务1】没完成的情况下去启动【任务2】
四、进程与线程
1.进程:
(1).一个正在运行的程序或软件,背后就对应着一个或多个进程。
(2).进程是操作系统进行资源分配的基本单位。
(1).每个进程都有自己独立的一块内存空间。
2.线程:
(1).线程是进程内部的执行单元(一个进程中可以有多个线程)
(2).线程是操作系统进行CPU调度的基本单位
(3).同一进程内的线程共享进程资源。
2. 使用Process创建进程
# 定义一个 speak 函数,功能是: 每隔一秒说话一次(一共说话10次)
import os
import time
from multiprocessing import Process
def speak():
for index in range(1,11):
print(f'我在说话{index},进程pid是:{os.getpid()}')
time.sleep(1)
# 定义一个 study 函数,功能是: 每隔一秒学习一次(一共学习15次)
def study():
for index in range(1,16):
print(f'我在学习{index},进程pid是:{os.getpid()}')
time.sleep(1)
# speak()
# study()
# 注意: 一定要写 if __name__ == '__main__' 这个判断,原因如下:
# 1.当创建子进程时,Python 并不会把父进程内存里的speak函数直接交给子进程
# 2.Python会启动一个全新的 Python解释器进程,重新执行当前的 .py 文件(作为模块)
# 3.在执行过程中,重新定义出一个 speak 函数,交给子进程。
if __name__ == '__main__':
# 创建两个 Process 类的实例对象(进程对象),分别是p1和p2
# 注意点1: p1 和 p2 就对应着以后的两个子进程,在创建它们的时候,就要指定好他们要执行的任务。
# 注意点2: 此时的 p1 和 p2 只是代码层面的两个进程对象,操作系统还没有真的创建 p1 和 p2 两个进程。
p1 = Process(target=speak)
p2 = Process(target=study)
# 调用进程对象的 start 方法,会立刻向操作系统申请一个进程,并且会将该进程交由操作系统进行调度。
p1.start()
p2.start()