Pandas
Pandas 是 Python 语言的一个扩展程序库,用于数据分析,提供高性能、易于使用的数据结构和数据分析工具
Pandas是基于NumPy构建的专门为处理表格和混杂数据设计的Python库,核心设计理念包括:
- 标签化数据结构: 提供带标签的轴
- 灵活处理缺失数据: 内置NaN处理机制
- 智能数据对齐: 自动按标签对齐数据
- 强大IO工具: 支持从CSV、Excel、SQL等20+数据源读写
- 时间序列处理: 原生支持日期时间处理和频率转换
Serires
1. Series 的创建
- 基础的创建
# series的创建
import pandas as pd
s = pd.Series([10,2,3,4,5])
# print(s)
# 自定义索引
s = pd.Series([10,2,3,4,5],index=['A','B','C','D','E'])
# 定义name
s = pd.Series([10,2,3,4,5],index= ['A','B','C','D','E'],name='月份')
print(s)- 通过字典的方式来创建
# 通过字典的方式来创建
s = pd.Series({'A':1,'B':2,'C':3,'D':4,'E':5},name='月份')
print(s)
s1 = pd.Series(s,index = ['A','C'])
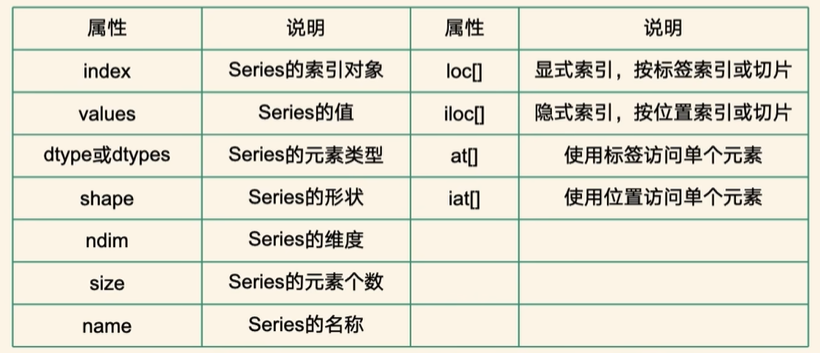
print(s1)2. Series常用的属性
s = pd.Series({'a':1,'b':2,'c':3,'d':4,'e':5},name='月份')
print(s)
print('索引',s.index) #
print('值',s.values) # 值
print('形状',s.shape) # 形状
print('维度',s.ndim) # 维度
print('数量',s.size) # 数量
s.name = 'test'
print('类型',s.dtype)
print('名字',s.name)
print('显示索引',s.loc['b'])
print('隐士索引',s.iloc[1])
print('显示索引切片',s.loc['a':'c'])
print('显示索引',s.at['a']) # 不支持切片的
print('隐士索引',s.iat[0]) # 不支持切片的3. 访问series数据
- 通过索引访问
#
# print(s[1]) # 不推荐
print(s['a'])- 布尔索引(与NumPy类似)
print(s)
print(s[s < 3])- s.head() 和 s.tail() 获取默认前/后5行数据
s['f'] = 6
print(s.head())
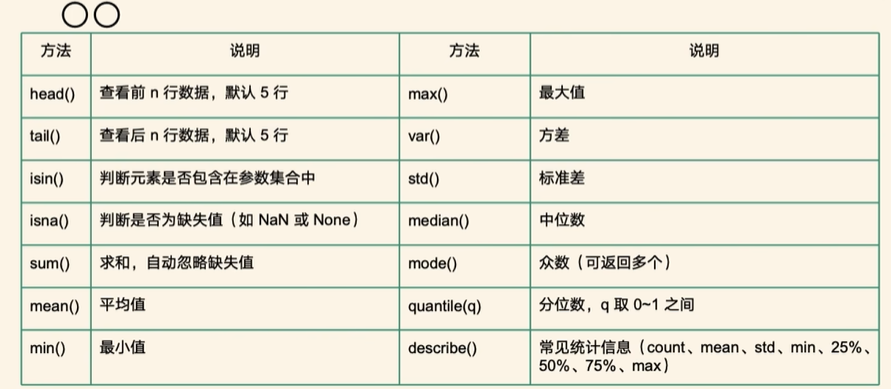
print(s.tail())4. Series的常用方法
- s.head() 和 s.tail() 获取默认前/后5行数据
# 默认取前5行数据
print(s.head())
# 默认取后5行数据
print(s.tail())
# 取前2行数据
print(s.head(2))
# 取后2行数据
print(s.tail(2))- s.describe() 查看所有的描述信息
# 查看所有的描述信息
s.describe()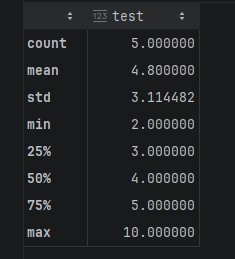 3. 获取元素个数(忽略缺失值)
3. 获取元素个数(忽略缺失值)
# 获取元素个数
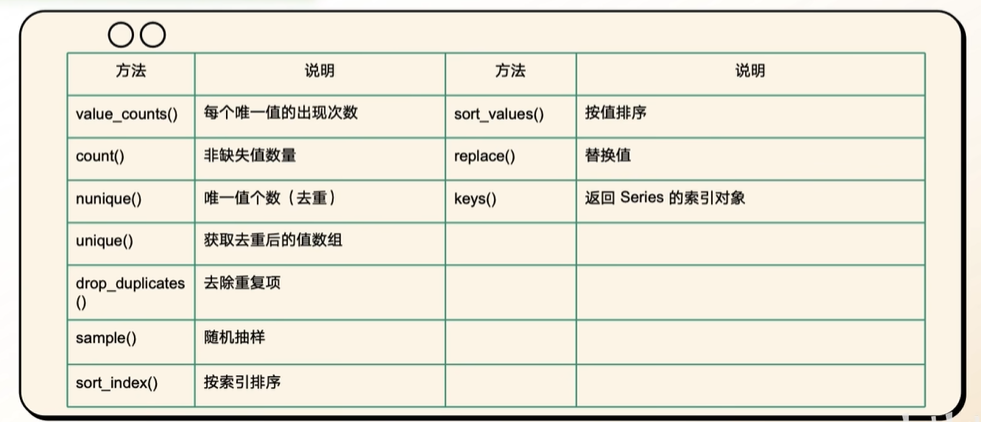
print(s.count())- 获取索引
s.keys() # 方法
print(s.index) # 属性- 检查Series中每一个元素是否是缺失值
s.isna()- 用来检查每个元素是否在参数集合中
s.isin([4])
s.isin([4,5])
s.isin([4,5,6])- 常用的方法
print(s.mean()) # 平均值
print(s.sum()) # 求和
print(s.std()) # 标准差
print(s.var()) # 方差
print(s.min()) # 最小值
print(s.max()) # 最大值
print(s.median()) # 中位数
print(s.sort_values()) # 排序
print(s.quantile(0.25)) # 分位数
print(s.mode()) # 众数
print(s.value_counts) # 每个元素的计数- 去重
s.drop_duplicates() # 去除重复值,返回的是Series对象
s.unique() # 去除重复值,返回的是数组
print(s.nunique()) # 去重后的元素个数- 排序
s.sort_index() # 按照索引排序
s.sort_values() # 按照值排序5. Serires练习1-学生成绩统计
创建一个包括10名学生成绩的Series,成绩范围在50-100之间。计算平均分、最高分、最低分
并找出高于平均分的学生人数。
np.random.seed(42)
scores = pd.Series(np.random.randint(50,101,10),index=['学生'+str(i) for i in range(1,11)])
print(scores)
print('平均分:', scores.mean())
print('最高分:', scores.max())
print('最低分:', scores.min())
print('高于平均分的人数:', len(scores[scores > (scores.mean())]))6. Series练习2-温度数据分析
给定某城市一周每天的最高温度Series,完成以下任务:
找出温度超过30度的天数
计算平均温度
将温度从高到低排序
找出温度变化最大的两天
temperatures.diff() 计算相邻元素之间的差值
temperatures = pd.Series([28,31,29,32,30,27,33],index=['周一','周二','周三','周四','周五','周六','周日'])
print('找出温度超过30度的天数',len(temperatures[temperatures>30]))
print('找出温度超过30度的天数',temperatures[temperatures>30].count())
print('计算平均温度',temperatures.mean())
print('将温度从高到底排序',temperatures.sort_values(ascending=False))
print(temperatures)
t3 = temperatures.diff().abs() # 计算series的变化值
print(*t3.sort_values(ascending=False).keys()[:2].tolist())
print('找出温度变化最大的两天',temperatures.sort_values(ascending=False))7. Series练习3-股票价格分析
给定某股票连续10个交易日的收盘价Series:
计算每日收益率(当日收盘价/前日收盘价 - 1)
找出收益率最高和最低的日期
计算波动率(收益率的标准差)
# 日期序列
date = pd.date_range('2025-06-1',periods=6)
print(date)
prices = pd.Series([102.2,103.5,105.1,104.8,106.2,107.0,106.5,108.1,109.3,110.2],index=pd.date_range('2023-01-01',periods=10))
#计算每日收益率(当日收盘价/前日收盘价) - 1
a = prices.pct_change()
print(a)
print('收益率最高的日期')
print(a.idxmax())
print('收益率最低的日期')
print(a.idxmin())
print('计算波动率(收益率的标准差)')
print(a.std())8. Series练习4-销售数据分析
某产品过去12个月的销售量Series:
计算季度平均销量(每3个月为1个季度)
找出销量最高的月份
计算月环比增长率
找出连续增长超过2个月的月份
sales = pd.Series([120,135,145,160,155,170,180,175,190,200,210,220],index=pd.date_range('2022-01-01',periods=12,freq='ME'))
print(prices)
# 季度的平均销量
sales.resample('QS').mean()
# 销量最高的月份
sales.idxmax()
print(sales.idxmax())
# 计算月环比的增长率
sales.pct_change()
# 找出连续增长超过两个月的月份
b = sales.pct_change() > 0
list(b[b.rolling(3).sum() == 3].keys())8. Series练习5-每小时销售数据分析
某商店每小时销售额Series:
按天重采样计算每日总销售额
计算每天营业时间(8:00-22:00) 和 非营业时间的销售额比例
找出销售额最高的3个小时
np.random.seed(42)
hours_sales = pd.Series(np.random.randint(0,100,24),index = pd.date_range('2025-01-01',periods=24,freq='h'))
print(hours_sales)
# 按天重采样计算每日总销售额
day_sales = hours_sales.resample('D').sum()
# 计算每天营业时间(8:00-22:00) 和非营业时间的销售额比例
# time = hours_sales.between_time("8:00","22:00") #筛选一段时间内的sales
business_hours_sales = hours_sales[(hours_sales.index.hour>=8) & (hours_sales.index.hour<=22)]
print(business_hours_sales)
not_business_hours_sales = hours_sales.drop(business_hours_sales.index)
print(business_hours_sales)
print(not_business_hours_sales)
print(business_hours_sales.sum()/not_business_hours_sales.sum())
# 找出销售额最高的3个小时
print("销售额最高的3个小时")
print(hours_sales.nlargest(3))DataFrame
DataFrame是Pandas中最常用的数据结构,它是一个二维的、大小可变的、异构的数据结构。它可以被看作是一张表格,其中包含行和列。DataFrame中的每一列可以是不同的数据类型(数值型、字符串等),并且可以拥有自己的索引。
1. DataFrame的创建
- 通过series来创建
import pandas as pd
import numpy as np
#
s1 = pd.Series([1,2,3,4,5])
s2 = pd.Series([6,7,8,9,10])
df = pd.DataFrame({"第一列": s1,"第二列": s2})
df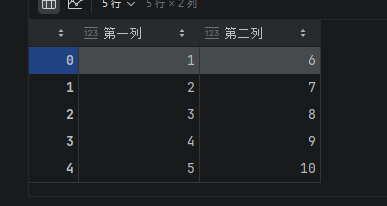
- 通过字典来创建
# 通过字典来创建
df = pd.DataFrame({
"id": [1,2,3,4,5],
"name":["tom",'jack','alice','bob','allen'],
"age":[15,17,20,26,30],
"score": [60.5,80,30.6,70,83.5]
},index=[1,2,3,4,5],columns=["id","name","age","score"])
df
df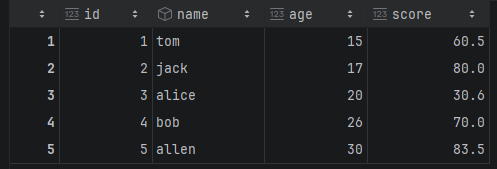
2. DataFrame的属性
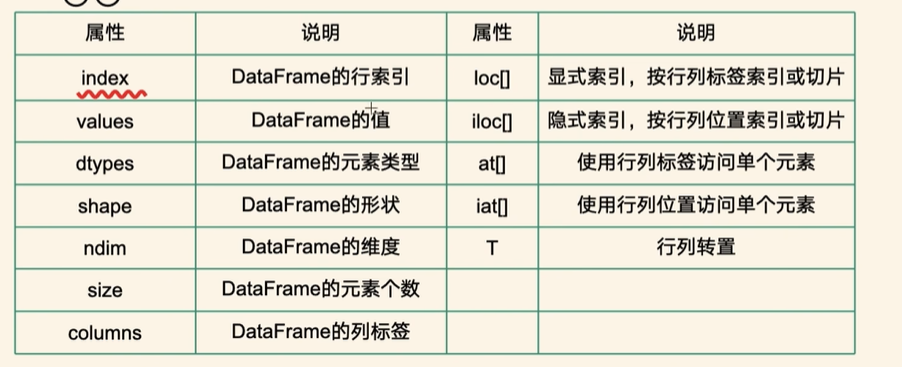
# dataFrame 的属性
print('行索引:' )
print(df.index)
print('列标签')
print(df.columns)
print('值')
print(df.values)
print('维度')
print(df.ndim)
print('形状')
print(df.shape)
print('元素个数')
print(df.size)
print('数据类型')
print(df.dtypes)
# 行列转置
# print(df.T)
df
# 获取元素 loc iloc at iat
# 某行
# df.loc[4] # 显示索引
# df.iloc[3] # 隐式索引
# 某列数据
df.loc[:,'name']
df.iloc[:,1]
# 单个元素
print(df.at[3,'name'])
print(df.iat[2,1])
print(df.loc[3,'name'])
print(df.iloc[2,1])3. 访问DataFrame的数据
获取单列数据
# 获取单列数据
print(df['name'])
print(df.name)
print(type(df.name))
print(df[['name']])
print(type(df[['name']]))多列的数据
print(df[['name','score']]) # 多列的数据查看部分数据
# 查看部分数据
print(df.head(2)) # 前两行的数据
print(df.tail(2)) # 后两行的数据布尔索引筛选数据
# 布尔索引筛选数据
df[df.score > 70] # 布尔索引筛选数据
df[(df.score > 70) & (df.age < 20)]随机抽样
# 随机抽样
df.sample(3)4. DataFrame的常用方法
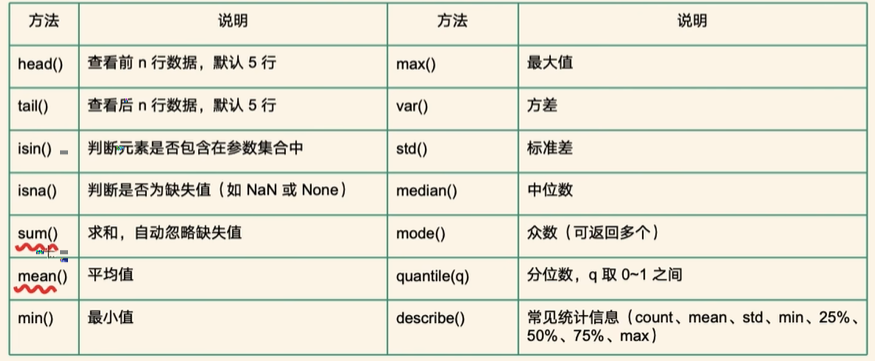
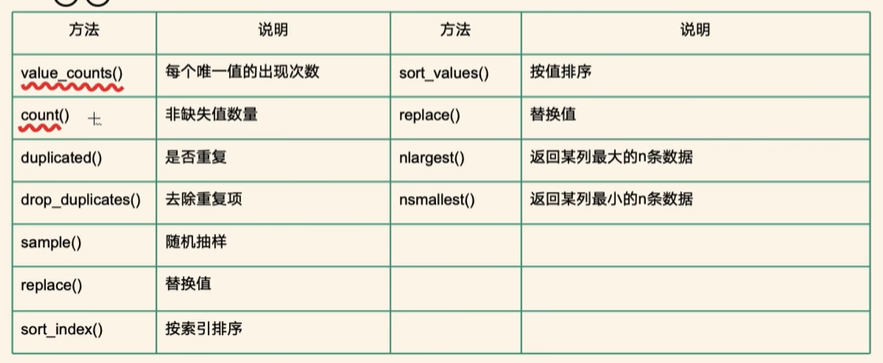
查看元素是否包含在参数集合中
print(df.isin(['jack',20])) # 查看元素是否包含在参数集合中查看元素是否是缺失值
print(df.isna()) # 查看元素是否是缺失值某一列求和
print(df['score'].sum())最大值
df.score.max()最小值
df.score.min()平均数
df.score.mean()中位数
df.score.median()众数
df.score.mode()标准差
print(df.score.std())方差
print(df.score.var())分位数
print(df.score.quantile(0.25))描述信息
df.describe()每一列非缺失值的个数
print(df.count())值出现的次数
print(df.value_counts()) # 出现的次数去重
print(df.drop_duplicates()) # 去重查看是否重复
print(df.duplicated(subset=['name']))随机采样
df.sample(3)替换值
df.replace(15,30) # 替换值累计和
df.cumsum() # 累计和累计积
df.cumsum() # 累计积
print(df.cummin(axis=0)) # 累计最小值排序
print(df.sort_index(ascending=False)) #按索引排序
print(df.sort_values(by='score')) # 按值排序
print(df.sort_values(by=['score','age'])) # 按值排序df.nlargest(3,columns=['score','age']) # 最大的三个值
df.nsmallest(2,columns=['score','age']) # 最小的三个值数据分析的完整流程
- 收集数据(数据从哪里来)
- 数据清洗
- 缺失值、错误数据、格式混乱
- 错误数据
- 格式混乱
- 数据分析
- 统计(平均值、最大值、比例)
- 分组对比(如男vs女用户的消费差异)
- 数据可视化(一图胜千言)
- 折线图(趋势)
- 柱状图(对比)
- 散点图(相关性)